| MATLAB Function Reference | |
事前共軛傾斜(Preconditioned Conjugate Gradients)法
Syntax
x = pcg(A,b) pcg(A,b,tol) pcg(A,b,tol,maxit) pcg(A,b,tol,maxit,M) pcg(A,b,tol,maxit,M1,M2) pcg(A,b,tol,maxit,M1,M2,x0) pcg(A,b,tol,maxit,M1,M2,x0,p1,p2,...) [x,flag] = pcg(A,b,tol,maxit,M1,M2,x0,p1,p2,...) [x,flag,relres] = pcg(A,b,tol,maxit,M1,M2,x0,p1,p2,...) [x,flag,relres,iter] = pcg(A,b,tol,maxit,M1,M2,x0,p1,p2,...) [x,flag,relres,iter,resvec] = pcg(A,b,tol,maxit,M1,M2,x0,p1,p2,...)
Description
x = pcg(A,b)
解線性方程式 A*x=b 的 x。n*n
的係數矩陣 A 必須為對稱且具正向定義(positive definite),而行向量 b 的長度為 n。A
可以是函數 afun 且 afun(x) 回傳 A*x。
若 pcg 收歛,將會顯示相關訊息。若 pcg
經過最大次數的重覆或任何理由被停止以致於沒有收歛,將會列印出一警告訊息顯示相關剩餘 norm(b-A*x)/norm(b),而該作法下的重覆數字也將停止。
pcg(A,b,tol)
定義容許誤差值。若 tol 為 [],則 pcg
使用預設值 1e-6。
pcg(A,b,tol,maxit)
定義重覆次數的最大值。若 maxit 為 [],則 pcg
使用預設值 min(n,20)。
pcg(A,b,tol,maxit,M) 及 pcg(A,b,tol,maxit,M1,M2)
使用先決條件 M 或 M = M1*M2
並有效地解方程式 inv(M)*A*x = inv(M)*b 的 x。若 M
為 [],則 pcg 不使用任何先決控制條件。M 可為一函式其回傳 M\x。
pcg(A,b,tol,maxit,M1,M2,x0)
定義初始的推測。若 x0 為 [],則
pcg
使用預設值。即全為零的向量。
pcg(afun,b,tol,maxit,m1fun,m2fun,x0,p1,p2,...)
傳送參數 p1,p2,... 至函數 afun(x,p1,p2,...), m1fun(x,p1,p2,...),
和 m2fun(x,p1,p2,...)。
[x,flag] = pcg(A,b,tol,maxit,M1,M2,x0)
亦回傳收歛旗標。
| 旗標 |
收歛性 |
0 |
pcg 在 maxit 次內收歛至期望的誤差 tol。 |
1 |
pcg 重覆 maxit 次但並沒有收歛。 |
2 |
先決條件 M 不夠完善。 |
3 |
pcg 沉滯(stagnated)。(兩次連續的重覆視為相同)。 |
4 |
當 flag 不為 0 時,解 x
回傳經由所有重覆次數的最小基準餘數(minimal norm residual)。若有定義 flag 的輸出,則不會顯示任何訊息。
[x,flag,relres] = pcg(A,b,tol,maxit,M1,M2,x0)
亦回傳相關餘數的估計值 norm(b-A*x)/norm(b)。若 flag
為 0,relres <= tol。
[x,flag,relres,iter] = pcg(A,b,tol,maxit,M1,M2,x0)
亦回傳 x 計算時的重覆次數,即 0 <= iter <= maxit。
[x,flag,relres,iter,resvec] = pcg(A,b,tol,maxit,M1,M2,x0)
亦回傳在每一次重覆的剩餘基準估計向量,包括 norm(b-A*x0)。
Examples
A = gallery('wilk',21);
b = sum(A,2);
tol = 1e-12;
maxit = 15;
M = diag([10:-1:1 1 1:10]);
[x,flag,rr,iter,rv] = pcg(A,b,tol,maxit,M);
function y = afun(x,n)
y = [0;
x(1:n-1)] + [((n-1)/2:-1:0)';
(1:(n-1)/2)'].*x + [x(2:n);
0];
function y = mfun(r,n) y = r ./ [((n-1)/2:-1:1)'; 1; (1:(n-1)/2)'];
[x1,flag1,rr1,iter1,rv1] = pcg(@afun,b,tol,maxit,@mfun,...
[],[],21);
A = delsq(numgrid('C',25));
b = ones(length(A),1);
[x,flag] = pcg(A,b)
flag 為 1 因為 pcg
在預設的外表重覆次數 20 內並沒有收歛至預設誤差 1e-6。
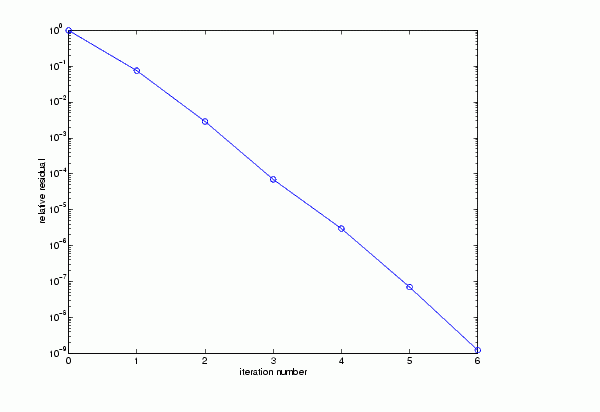
R = cholinc(A,1e-3); [x2,flag2,relres2,iter2,resvec2] = pcg(A,b,1e-8,10,R',R)
flag2 為 0 因為 pcg
在微量誤差為 1e-3 的不完全 Cholesky 分解法在第六次重覆時( iter2 的值)收歛至誤差值為 1.2e-9(即 relres2
的值)。resvec2(1) = norm(b) 且 resvec2(7) = norm(b-A*x2)。可藉由開始於初始估計的每一次重覆相關餘數平面圖來了解。
semilogy(0:iter2,resvec2/norm(b),'-o')
xlabel('iteration number')
ylabel('relative residual')
See Also
bicg, bicgstab, cgs, cholinc, gmres, lsqr, minres, qmr, symmlq
@ (function handle), \ (backslash)
References
[1] Barrett, R., M. Berry, T. F. Chan, et al., Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, SIAM, Philadelphia, 1994.
| | pbaspect | pchip | |