The simplest ASR application is voice command recognition. To construct a voice command recognizer, we need to collect training data for each voice command. This data is used for constructing an HMM for each voice command. For a given utterance, we need to send the corresponding acoustic features (MFCC, for example) to each HMM for evaluation the log probability. The HMM with the highest log probability represents the predicted voice command for the given utterance.
For simplicity in the following discussion, we shall assume our goal is to construct a speaker-independent digit recognizer that can recognize the utterance of 0 ~ 9. There are two steps involved in the design of such recognition system:
- Corpus collection: To achieve speaker independence, we need to have a wide collection of speech corpus, including:
- Subjects: We need to have utterances from various subjects, including different genders, different age groups, different accent (from different regions), etc.
- Recording devices: We need to use different microphones and different sound cards, etc.
- Environment: We need to have a recording environment that is close to that of the recognizer at application. To increase the robustness of the trained acoustic models, we should do the recording at quiet locations such as labs/offices, as well as noisy locations such as restaurants and road sides, etc.
- Recognizer design: We need to design a recognizer based on HMM and test its performance. This will be detailed in the rest of this section.
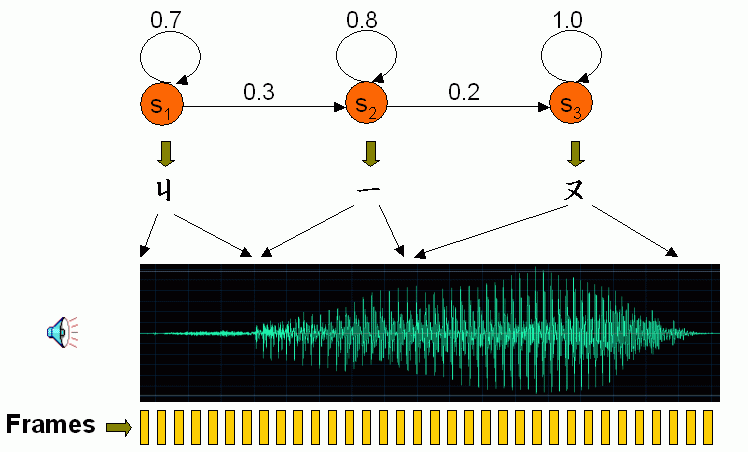
Before using DHMM, each frame is converted into a feature vector (such as MFCC), and each vector is transformed into a symbol. More specifically, all feature vectors are partitioned into clusters using vector quantization. We then use the index of a cluster to which a frame belongs to represent the symbol of that frame. That is, if the feature vector of frame i belongs to cluster k, then the symbol of frame i is k, as shown in the following expression:
- frameNum: The number of frames for a given utterance
- dim: The dimension of the acoustic features used in our recognizer. (For instance, the basic MFCC has 12 dimensions.)
- stateNum: the number of states in a DHMM
- symbolNum: The number of symbols, or equivalently, the number of clusters after vector quantization.
Usually we use the state and transition probabilities to characterize a given DHMM, as follows.
- We use a stateNum×stateNum matrix A to denote the transition probability, in which A(i, j) denotes the probability from state i to j. For instance, the probability of transition from state 1 to 2 is 0.3, hence A(1, 2) = 0.3. In general, A(i, j) satisfies the following conditions:
- State transitions are allowed only between neighboring states. Hence A(i, j) = 0 if j≠i and j≠i+1。
- For a given state, the self-state and next-state transition probabilities should sum to 1. Namely, A(i, i) + A(i, i+1) = 1, for all i.
- We use a symbolNum×stateNum matrix B to denote the state probability, in which B(k, j) denotes the probability to which symbol k belongs to state j. Therefore to compute the probability of frame i being generated by state j, we need to find the corresponding symbol k=O(i), and then retrieve the probability from B(k, j).
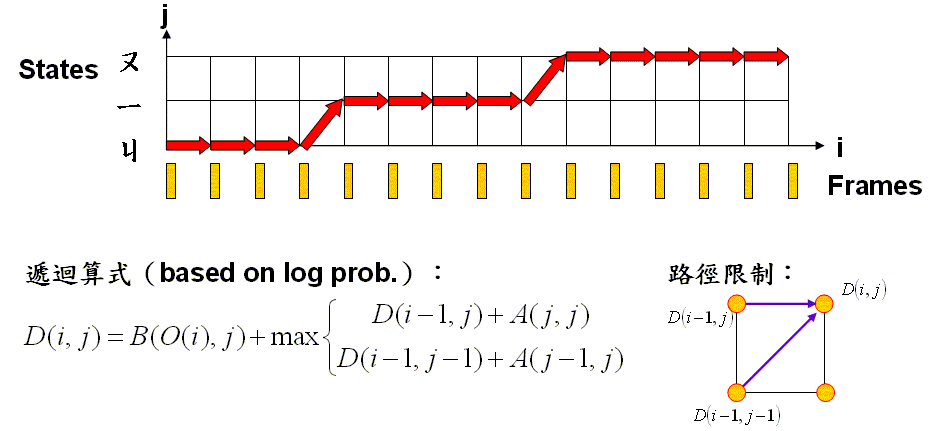
- The optimum-value function D(i, j) is defined as the maximum probability between t(1:i) and r(1:j), where t(1:i) the feature vectors of frame 1 to i, r(1:j) is the DHMM formed by state 1 to j. The optimum mapping path from (1, 1) to (i, j) is sought to minimize D(i, j).
- The recursion of D(i, j) can be expressed as follows:
D(i, j) = B(O(i), j) + max{D(i-1, j)+A(j, j), D(i-1, j-1)+A(j-1, j)}. The boundary conditions isD(1, j) = p(1, j) + B(O(1), j), j = 1 ~ stateNum, where p(1, j) denotes the initial state probability for state j. - The final answer is D(m, n).
- Reduce the round-off errors due to repeated multiplications.
- Use addition instead of multiplication to reduce computation load.
To evaluate the probability of frame i to state j, there are two different methods:
- For DHMM, we need to find the corresponding symbol O(i) and then look up the value of B(O(i), j) from matrix B.
- For CHMM, B(O(i),j) is defined by a continuous probability density function. Please refer to the next section for detail.
The procedure to find the optimum values of A and B is called re-estimation. The basic concept is close to that of k-means (Forgy's method) which identify parameters by Picard iteration. That is, we can guess the values of A and B first, then perform Viterbi decoding, and then identify A and B again based on the given optimum path, until the values of A and B converge. We can prove that during the iterations, the total probability will increase monotonically. However, we cannot guarantee the identify values of A and B is the global optimum values. The steps of re-estimation are explained next.
- Convert all utterances into acoustic features, say, 39-dimensional MFCC.
- Perform vector quantization on all feature vectors and find the symbol (index of a cluster center) of each feature vector.
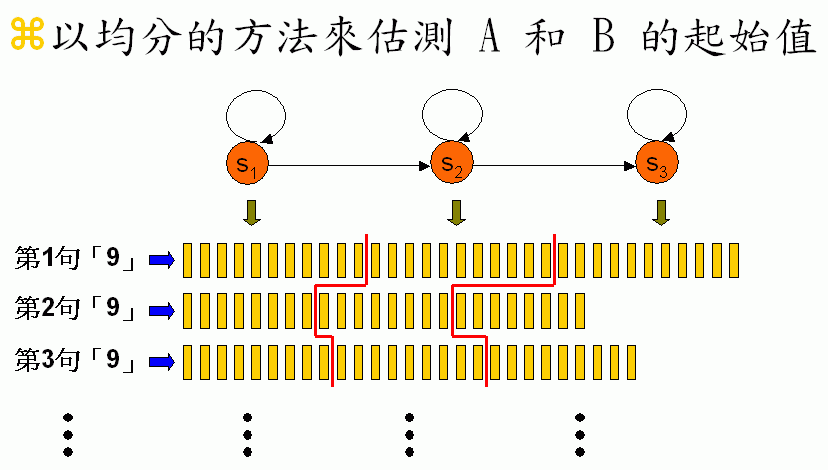
- Guess the initial values of A and B. If there is no manual transcription, we can adopt the simple strategy of "equal division" shown next.
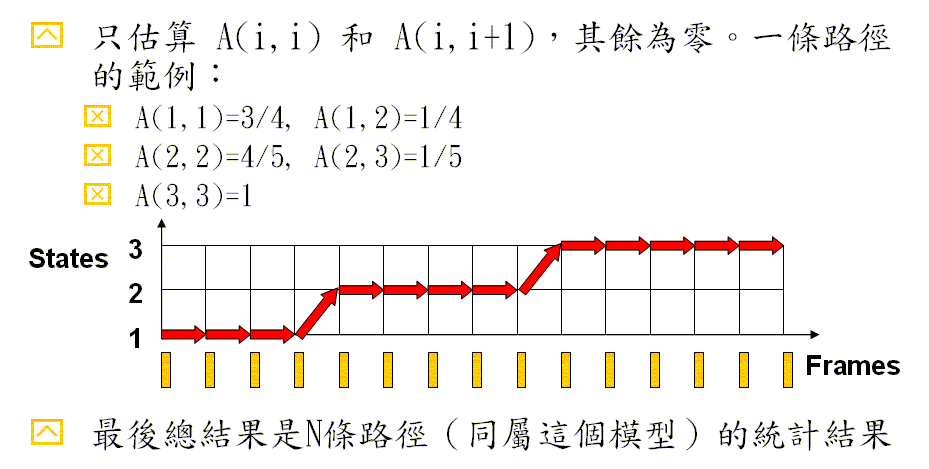
- Iterate the following steps until the values of A and B converge.
- Viterbi decoding: Given A and B of an DHMM, find the optimum mapping paths of all the corresponding utterances of this DHMM.
- Re-estimation: Use the optimum mapping paths to estimate the values of A and B.

- State 1: C(1,1)=B(2,1)=1/4, C(2,1)=B(1,1)=1/4, C(3,1)=B(3,1)=2/4, C(4,1)=B(3,1)=2/4
- State 2: C(5,2)=B(1,1)=3/5, C(6,2)=B(1,1)=3/5, C(7,2)=B(2,1)=2/5, C(8,2)=B(1,1)=3/5, C(9,2)=B(2,1)=2/5
- State 2: C(10,3)=B(4,3)=4/6, C(11,3)=B(4,3)=4/6, C(12,3)=B(4,3)=4/6, C(13,3)=B(2,3)=2/6, C(14,3)=B(2,3)=2/6, C(15,3)=B(4,3)=4/6
If we use P(A, B, Path) as our objective function, then the above re-estimation can guarantee the monotonic increasing of the objective function, based on the following two facts.
- When A and B is given, Viterbi decoding can find the optimum mapping path to maximize P(A, B, Path).
- When the mapping path (Path) is given, re-estimation can find the optimum A and B to maximize P(A, B, Path).
Take the above example for instance, the probability of the given path can be decomposed into three components based on each state:
- State 1: C(1,1)A(1,1)C(2,1)A(1,1)C(3,1)A(1,1)C(4,1)A(1,2) = A(1,1)3A(1,2)C(1,1)C(2,1)C(3,1)C(4,1)
- State 2: C(5,2)A(2,2)C(6,2)A(2,2)C(7,2)A(2,2)C(8,2)A(2,2)C(9,2)A(2,3) = A(2,2)4A(2,3)C(5,2)C(6,2)C(7,2)C(8,2)C(9,2)
- State 3: C(10,3)A(3,3)C(11,3)A(3,3)C(12,3)A(3,3)C(13,3)A(3,3)C(14,3)A(3,3)C(15,3) = A(3,3)5C(10,3)C(11,3)C(12,3)C(13,3)C(14,3)C(15,3)
First of all, we shall derive the optimum value of matrix A. For any given state, we can define the following quantities:
- a: self-transition count (known)
- b: next-transition count (known)
- p: self-transition prob. (unknown)
- q: next-transition prob. (unknown)
Secondly, we shall derive the optimum value of B. For any given state, assume that frames of this state belong to 3 clusters. We can define the following quantities:
- Symbol count: a, b, c (known)
- State prob: p, q, r (unknown)
Therefore by decomposing the total probability of N paths into the probability associated with each state, we can identify the optimum values of the transition and state probabilities of this state. This completes the coverage of re-estimation which can guarantee the monotonic non-decreasing of the total log probability.
Data Clustering and Pattern Recognition (資料分群與樣式辨認)
