dpOverMap
DP over matrix of state probability.
Contents
Syntax
- optimValue=dpOverMap(stateProbMat, transProbMat)
- optimValue=dpOverMap(stateProbMat, transProbMat, showPlot)
- [optimValue, dpPath, dpTable, time]=dpOverMap(...)
Description
[optimValue, dpPath]=dpOverMap(stateProbMat, transProbMat) returns the optimum value and the corresponding DP (dynamic programming) for HMM evaluation.
- stateProbMat: matrix of log state probabilities
- transProbMat: matrix of log transition probabilities
Example
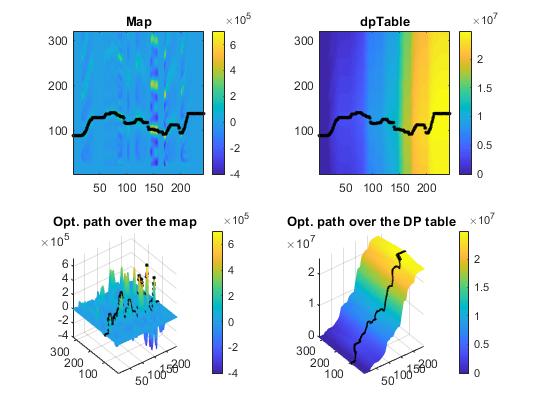
load pfMat.mat pfMat(1:20, :)=0; %pfMat=[5 2 6; 2 9 3]; [stateNum, frameNum]=size(pfMat); penalty=10000; opt.initProb=log(1/stateNum)*ones(1, stateNum); %opt.initProb=zeros(1, stateNum); opt.initProb(1)=1; opt.initProb=log(opt.initProb); opt.endState=logical(ones(1, stateNum)); %opt.endState=logical(zeros(1, stateNum)); opt.endState(end)=1; showPlot=1; [optimValue, dpPath, dpTable, time]=dpOverMap(pfMat, penalty, opt, showPlot); fprintf('Time=%.2f sec\n', time);
Time=0.02 sec