cvDataGen
Generate m-fold cross validation (CV) data for performance evaluation
Contents
Syntax
- cvData=cvDataGen(DS)
- cvData=cvDataGen(DS, opt)
- cvData=cvDataGen(DS, opt, showPlot)
- [cvData, dispatchMat4index, dispatchMat4output]=cvDataGen(...)
Description
[cvData, count]=cvDataGen(DS, m, mode) generates m-fold cross-validation data for performance evaluation.
- DS: dataset to be partitioned
- m: number of folds
- mode: 'index' (index only, default) or 'full' (full data)
The m-fold CV data is generated to satisfy the following two criteria:
- Each fold has the same number (or as close as possible) of data instances.
- Each fold has the same (or as close as possible) class distribution.
You can examine the class distribution via the matrix count, where count(i,j) is the number of instances of class i within fold j.
If the mode is "full", then cvData is a structure array of m elements, with "TS" and "VS" fields for "training set" and "validating set", respectively.
If the mode is "index", then both cvData.TS and cvData.VS contain only the indices of the original data for saving memory.
Example
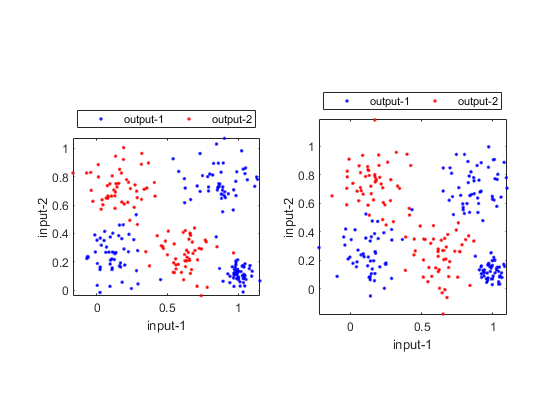
DS=prData('nonlinearseparable'); opt=cvDataGen('defaultOpt'); opt.foldNum=2; opt.cvDataType='full'; cvData=cvDataGen(DS, opt); subplot(121); dsScatterPlot(cvData(1).TS); subplot(122); dsScatterPlot(cvData(1).VS);