- (*) Cross validation:
Explain the following methods for performance evaluation of classifiers:
- Hold-out test
- Two-way hold-out test
- m-fold cross validation
- Leave-one-out cross validation
- (**) About m-fold cross validation:
- Explain the basic principle of m-fold cross validation.
- What are the strength and drawback of it when compared with one-sided holdout test?
- (**) About leave-one-out cross validation:
- Explain the basic principle of leave-one-out cross validation.
- What are the strength and drawback of it when compared with m-fold cross validation (where m is less than the size of the training dataset)?
- (**) LOO CV for QC:
What is your strategy to save computation as much as possible if you want to compute LOO cross validation for
- QC
- NBC
- (**) 5-fold cross validation on IRIS using 1-NNC:
Write a script to perform 5-fold cross validation on the Iris dataset using 1-NNC.
- What is the outside-test recognition for each fold of the 5-fold cross validation?
- What is the overall outside-test recognition rate?
- (**) 5-fold cross validation on WINE using 1-NNC: Repeat the previous exercise by using the WINE dataset.
- (**) Speeding up LOOCV of QC:
By using perfCv.m, it is pretty easy to compute the training and validation accuracy via LOOCV (leave-one-out cross validation). Here is an example which performs LOOCV on the IRIS dataset:
However, perfCv.m performs LOOCV by viewing the model construction as a black box. To speed up LOOCV, we can take advantage of our insight into the model construction and try to compute a common part that can be used repeatedly. For the model construction without the k-th I/O pairs, we can simply perform a quick update to obtain the new models. You mission in this exercise is to write a function myPerfCv.m that can perform fast LOOCV using QC, with the following format:[vRr, tRr]=myPerfCv(DS); where vRr and tRr are the validation and training recognite rates, respectively.
Hint: You should compute common parts first- $\mu_{all}=\frac{1}{n} \sum_{i=1}^n x_i$
- $\Sigma_{all} = \frac{1}{n} \sum_{i=1}^n (x_i-\mu_{all})(x_i-\mu_{all})^T$
- (**) Speeding up LOOCV of NBC: Repeat the previous exercise by using NBC (naive Bayes classifier).
- (**) Determine the best number of centers for VQ-based 1-NNC:
Write a script to determine the best number of centers for VQ-based 1-NNC using LOOCV. Specifically, you should follow the steps:
- For a given dataset, you should be able to run perfCv.m to return the LOO validation and training RRs for a given value of c (the number of the centers for VQ-based 1-NNC). Here are two examples for your reference:
- Increase the value of c and and plot the validation RR (vRr) and the training RR (tRr) as two curves with respect to c.
- In fact, the value of c represents the complexity of the classifier. Can you observe the phenomenon that the training RR goes up with c all the way, while the validation RR goes up initially and then fall off eventually? Please plot the curves and show the plot to TA. At which value of c the validation RR achieves its maximum?
This is the resuslt for WINE dataset: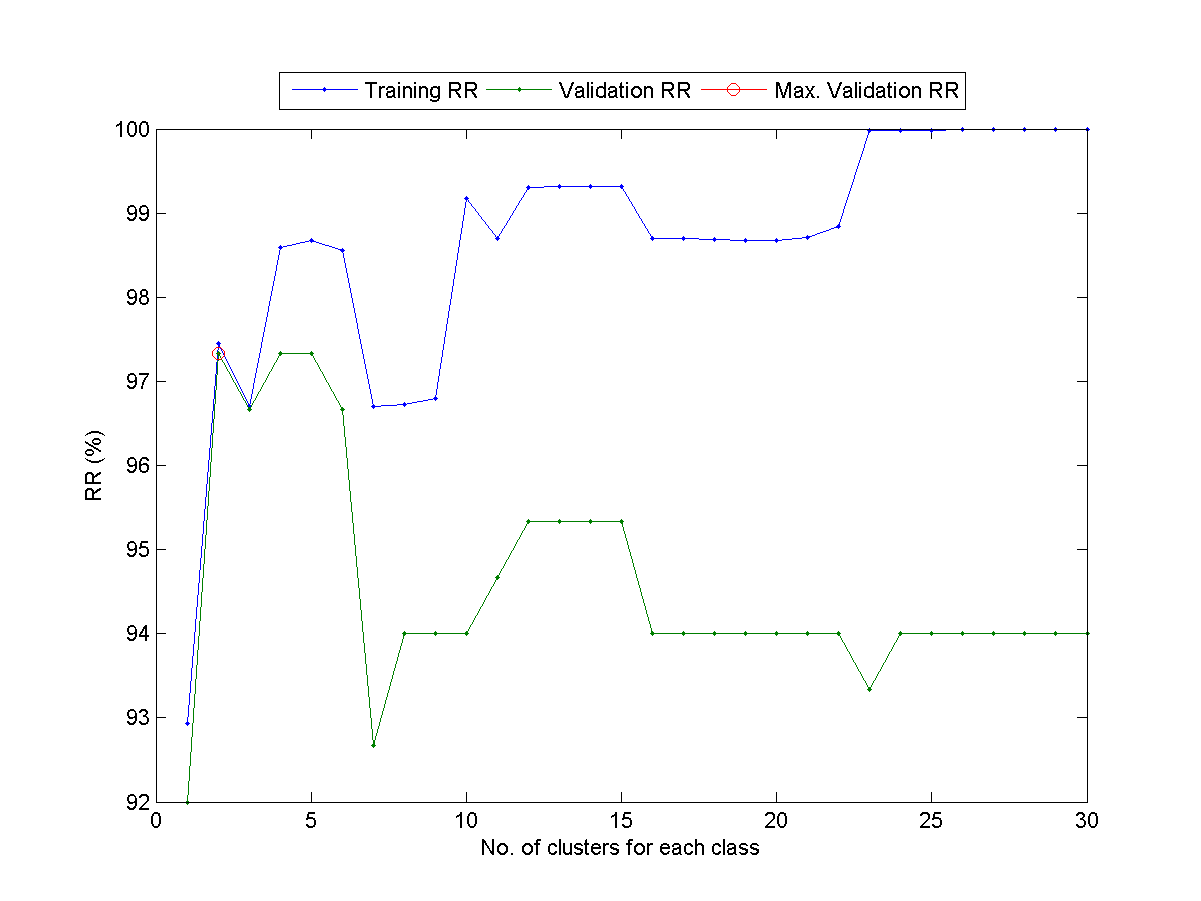
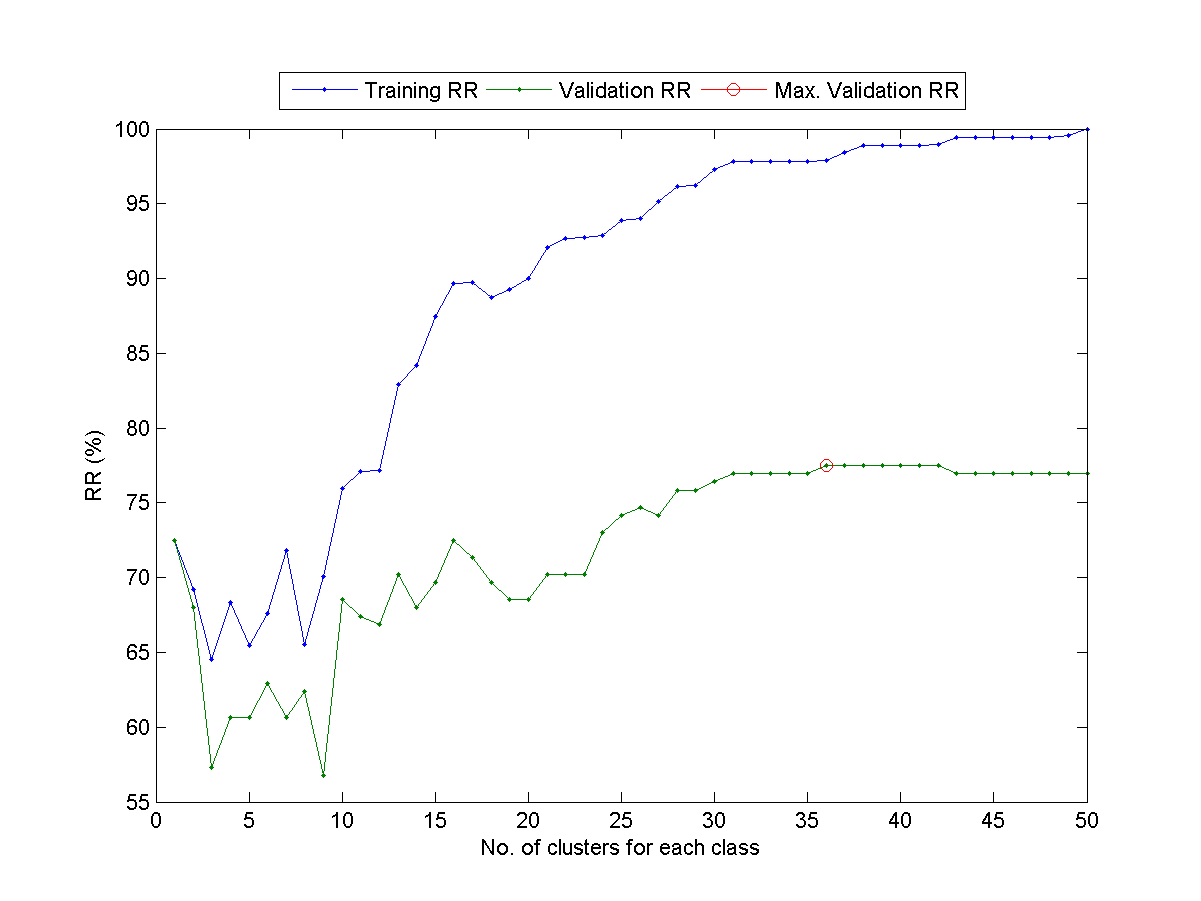
- (*) Train and evaluate a classifier:
Write a function myTrainTest.m to train and evaluate a classifier based on given training and test datasets. The usage of the function is
[trainRr, testRr]=myTrainTest(ds4train, ds4test, classifier) where- ds4train: dataset for training
- ds4test: dataset for testing
- classifier: 'qc' for quadratic classifier, 'nbc' for naive Bayes classifier
- trainRR: recognition rate of training
- testRr: recognition rate of testing
Test script:
Data Clustering and Pattern Recognition (資料分群與樣式辨認)
