Tutorial on gender classification
In this tutorial, we shall explain the basics of gender classification based on a person's attributes, including height, weight, palm width, highest pitch, and lowest pitch. The dataset was collected from students at the class of Scientific Computing in Fall 2015, at CSIE Department, National Taiwan University.
Contents
Preprocessing
Before we start, let's add necessary toolboxes of Utility and Machine Learning to the search path of MATLAB:
addpath d:/users/jang/matlab/toolbox/utility addpath d:/users/jang/matlab/toolbox/machineLearning
For compatibility, here we list the platform and MATLAB version that we used to run this script:
fprintf('Platform: %s\n', computer); fprintf('MATLAB version: %s\n', version); scriptStartTime=tic;
Platform: PCWIN64 MATLAB version: 8.5.0.197613 (R2015a)
Dataset construction
First of all, we shall read the collected data from a tsv file gender.tsv:
dataFile='gender.tsv'; fieldName={'time', 'gender', 'height', 'weight', 'palmWidth', 'pitchHigh', 'pitchLow', 'id'}; table=tableRead(dataFile, 1, fieldName); table(1)=[]; for i=1:length(table) table(i).height=eval(table(i).height); table(i).weight=eval(table(i).weight); table(i).palmWidth=eval(table(i).palmWidth); table(i).pitchHigh=eval(table(i).pitchHigh); table(i).pitchLow=eval(table(i).pitchLow); end
After reading the data, we need to organize it into a specific format for the Machine Learning Toolbox:
ds.inputName={'height', 'weight', 'palmWidth', 'pitchHigh', 'pitchLow'};
ds.outputName={'男', '女'};
for i=1:length(table)
for j=1:length(ds.inputName)
ds.input(j,i)=table(i).(ds.inputName{j});
end
ds.output(i)=find(strcmp(table(i).gender, ds.outputName));
end
Dataset visualization
Once we have every piece of necessary information stored in "ds", we can invoke many different functions in Machine Learning Toolbox for data visualization and classification.
For instance, we can display the size of each class:
figure; [classSize, classLabel]=dsClassSize(ds, 1);
5 features 60 instances 2 classes
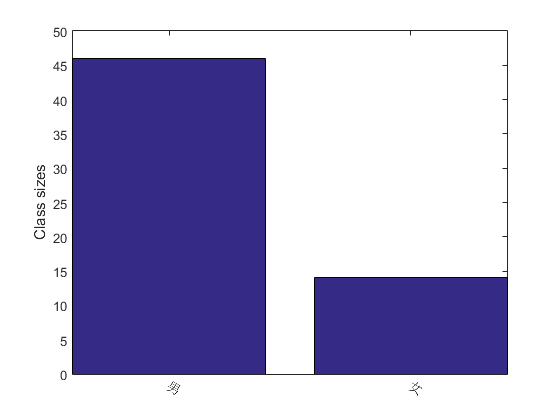
We can plot the range of each feature in the dataset:
figure; dsRangePlot(ds);
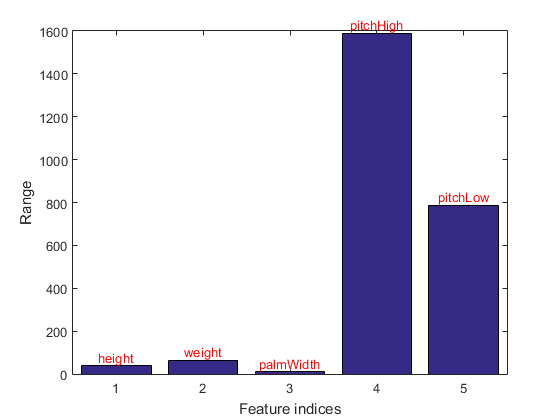
The above plot only plot the ranges of features. To be more precise, we can plot the distribution of each features within each class:
figure; dsBoxPlot(ds);
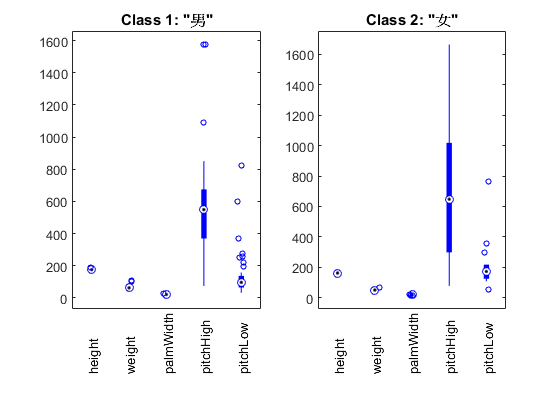
We can plot each feature vs. the index. This plot is more meanful if we put instances of the same class to have close indices:
ds2=ds; [ds2.output, index]=sort(ds2.output); ds2.input=ds2.input(:, index); figure; dsFeaVsIndexPlot(ds2);
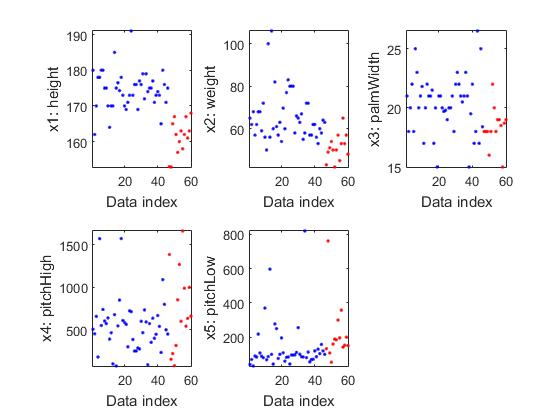
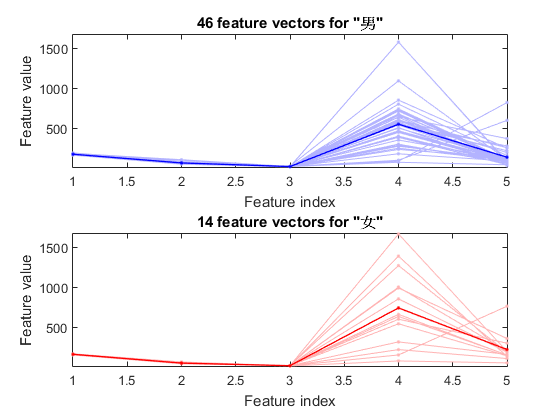
We can plot the feature vectors within each class:
figure; dsFeaVecPlot(ds);
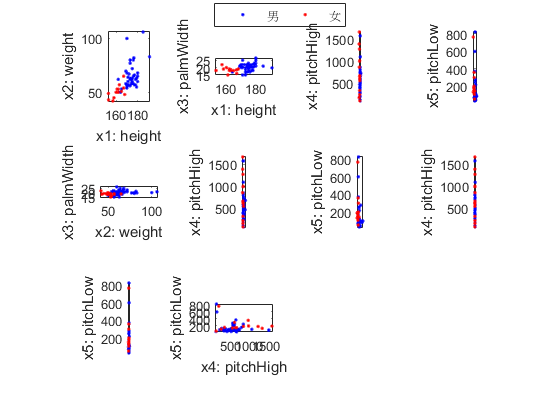
We can do the scatter plots on every 2 features:
figure; dsProjPlot2(ds);
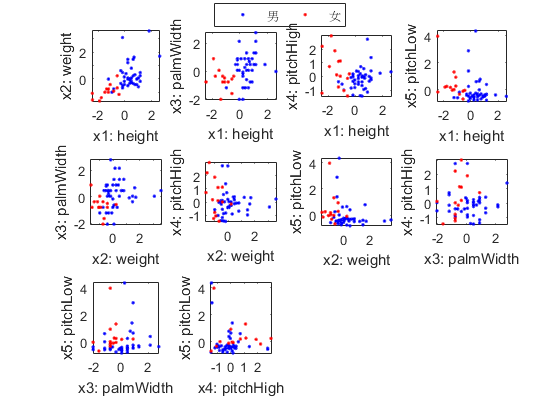
It is hard to see the above plots due to a large variation in the range of each features. To avoid this, we can simply perform z-normalization on the features and try the same plot:
ds2=ds; ds2.input=inputNormalize(ds2.input); figure; dsProjPlot2(ds2);
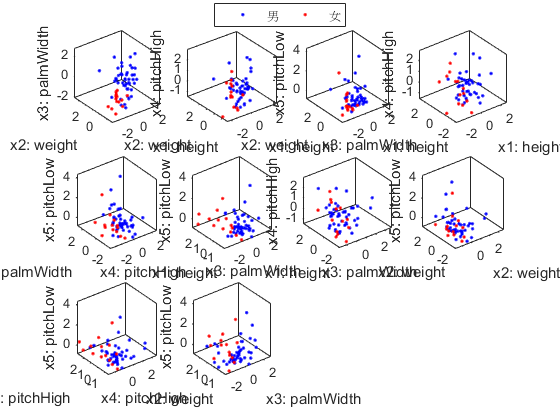
We can also do the scatter plots in the 3D space:
figure; dsProjPlot3(ds2);
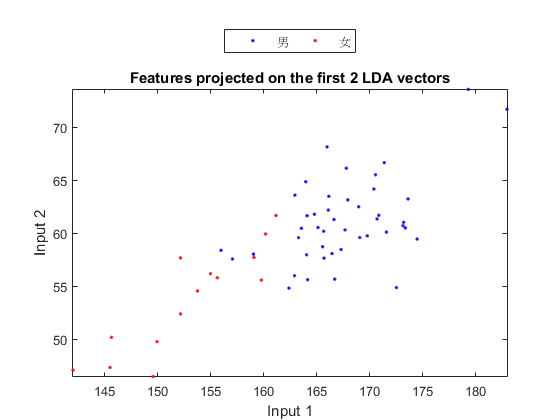
In order to visualize the distribution of the dataset, we can project the original dataset into 2-D space. This can be achieved by LDA (linear discriminant analysis):
ds2d=lda(ds); ds2d.input=ds2d.input(1:2, :); figure; dsScatterPlot(ds2d); xlabel('Input 1'); ylabel('Input 2'); title('Features projected on the first 2 LDA vectors');
Classification
We can try the most straightforward KNNC (k-nearest neighbor classifier):
rr=knncLoo(ds);
fprintf('rr=%g%% for ds\n', rr*100);
6/60 12/60 18/60 24/60 30/60 36/60 42/60 48/60 54/60 60/60 rr=66.6667% for ds
For normalized dataset, usually we can obtain a better accuracy:
[rr, computed]=knncLoo(ds2);
fprintf('rr=%g%% for ds2 of normalized inputs\n', rr*100);
6/60 12/60 18/60 24/60 30/60 36/60 42/60 48/60 54/60 60/60 rr=83.3333% for ds2 of normalized inputs
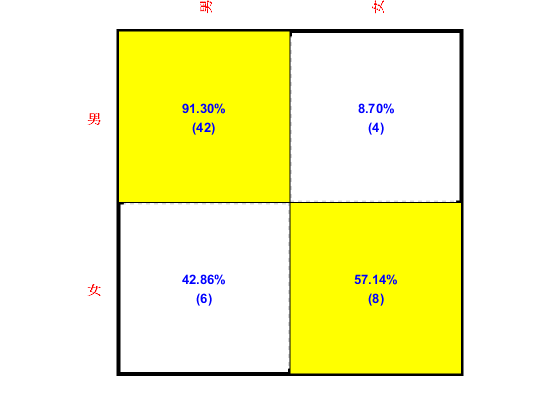
We can plot the confusion matrix:
confMat=confMatGet(ds2.output, computed); opt=confMatPlot('defaultOpt'); opt.className=ds.outputName; opt.mode='both'; figure; confMatPlot(confMat, opt);
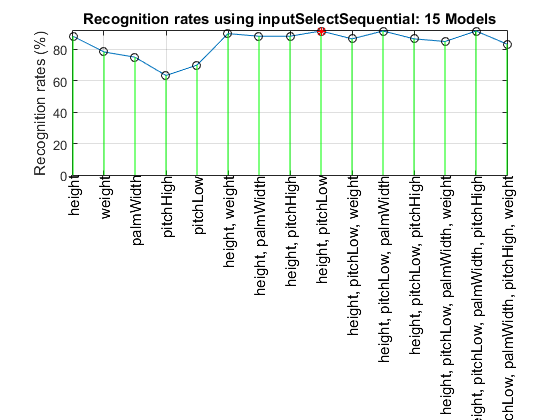
We can perform sequential input selection to find the best features:
figure; tic; inputSelectSequential(ds2, inf, 'knnc', 1); toc
Construct 15 KNN models, each with up to 5 inputs selected from 5 candidates...
Selecting input 1:
Model 1/15: selected={height} => Recog. rate = 88.3%
Model 2/15: selected={weight} => Recog. rate = 78.3%
Model 3/15: selected={palmWidth} => Recog. rate = 75.0%
Model 4/15: selected={pitchHigh} => Recog. rate = 63.3%
Model 5/15: selected={pitchLow} => Recog. rate = 70.0%
Currently selected inputs: height
Selecting input 2:
Model 6/15: selected={height, weight} => Recog. rate = 90.0%
Model 7/15: selected={height, palmWidth} => Recog. rate = 88.3%
Model 8/15: selected={height, pitchHigh} => Recog. rate = 88.3%
Model 9/15: selected={height, pitchLow} => Recog. rate = 91.7%
Currently selected inputs: height, pitchLow
Selecting input 3:
Model 10/15: selected={height, pitchLow, weight} => Recog. rate = 86.7%
Model 11/15: selected={height, pitchLow, palmWidth} => Recog. rate = 91.7%
Model 12/15: selected={height, pitchLow, pitchHigh} => Recog. rate = 86.7%
Currently selected inputs: height, pitchLow, palmWidth
Selecting input 4:
Model 13/15: selected={height, pitchLow, palmWidth, weight} => Recog. rate = 85.0%
Model 14/15: selected={height, pitchLow, palmWidth, pitchHigh} => Recog. rate = 91.7%
Currently selected inputs: height, pitchLow, palmWidth, pitchHigh
Selecting input 5:
Model 15/15: selected={height, pitchLow, palmWidth, pitchHigh, weight} => Recog. rate = 83.3%
Currently selected inputs: height, pitchLow, palmWidth, pitchHigh, weight
Overall maximal recognition rate = 91.7%.
Selected 2 inputs (out of 5): height, pitchLow
Elapsed time is 2.406661 seconds.
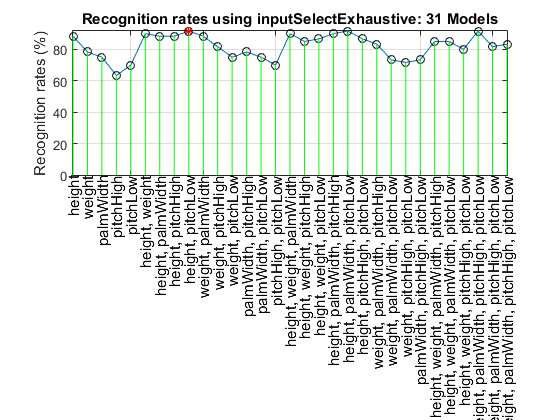
We can also perform exhaustive input selection, which is much slower:
figure; tic; inputSelectExhaustive(ds2, inf, 'knnc', 1); toc
Construct 31 KNN models, each with up to 5 inputs selected from 5 candidates...
modelIndex 1/31: selected={height} => Recog. rate = 88.333333%
modelIndex 2/31: selected={weight} => Recog. rate = 78.333333%
modelIndex 3/31: selected={palmWidth} => Recog. rate = 75.000000%
modelIndex 4/31: selected={pitchHigh} => Recog. rate = 63.333333%
modelIndex 5/31: selected={pitchLow} => Recog. rate = 70.000000%
modelIndex 6/31: selected={height, weight} => Recog. rate = 90.000000%
modelIndex 7/31: selected={height, palmWidth} => Recog. rate = 88.333333%
modelIndex 8/31: selected={height, pitchHigh} => Recog. rate = 88.333333%
modelIndex 9/31: selected={height, pitchLow} => Recog. rate = 91.666667%
modelIndex 10/31: selected={weight, palmWidth} => Recog. rate = 88.333333%
modelIndex 11/31: selected={weight, pitchHigh} => Recog. rate = 81.666667%
modelIndex 12/31: selected={weight, pitchLow} => Recog. rate = 75.000000%
modelIndex 13/31: selected={palmWidth, pitchHigh} => Recog. rate = 78.333333%
modelIndex 14/31: selected={palmWidth, pitchLow} => Recog. rate = 75.000000%
modelIndex 15/31: selected={pitchHigh, pitchLow} => Recog. rate = 70.000000%
modelIndex 16/31: selected={height, weight, palmWidth} => Recog. rate = 90.000000%
modelIndex 17/31: selected={height, weight, pitchHigh} => Recog. rate = 85.000000%
modelIndex 18/31: selected={height, weight, pitchLow} => Recog. rate = 86.666667%
modelIndex 19/31: selected={height, palmWidth, pitchHigh} => Recog. rate = 90.000000%
modelIndex 20/31: selected={height, palmWidth, pitchLow} => Recog. rate = 91.666667%
modelIndex 21/31: selected={height, pitchHigh, pitchLow} => Recog. rate = 86.666667%
modelIndex 22/31: selected={weight, palmWidth, pitchHigh} => Recog. rate = 83.333333%
modelIndex 23/31: selected={weight, palmWidth, pitchLow} => Recog. rate = 73.333333%
modelIndex 24/31: selected={weight, pitchHigh, pitchLow} => Recog. rate = 71.666667%
modelIndex 25/31: selected={palmWidth, pitchHigh, pitchLow} => Recog. rate = 73.333333%
modelIndex 26/31: selected={height, weight, palmWidth, pitchHigh} => Recog. rate = 85.000000%
modelIndex 27/31: selected={height, weight, palmWidth, pitchLow} => Recog. rate = 85.000000%
modelIndex 28/31: selected={height, weight, pitchHigh, pitchLow} => Recog. rate = 80.000000%
modelIndex 29/31: selected={height, palmWidth, pitchHigh, pitchLow} => Recog. rate = 91.666667%
modelIndex 30/31: selected={weight, palmWidth, pitchHigh, pitchLow} => Recog. rate = 81.666667%
modelIndex 31/31: selected={height, weight, palmWidth, pitchHigh, pitchLow} => Recog. rate = 83.333333%
Overall max recognition rate = 91.7%.
Selected 2 inputs (out of 5): height, pitchLow
Elapsed time is 4.821564 seconds.
We can even perform an exhaustive search on the classifiers and the way of input normalization:
opt=perfCv4classifier('defaultOpt'); opt.foldNum=inf; tic; [perfData, bestId]=perfCv4classifier(ds, opt, 1); toc structDispInHtml(perfData, 'Performance of various classifiers via cross validation');
Iteration=200/1000, recog. rate=42.3729% Iteration=400/1000, recog. rate=42.3729% Iteration=600/1000, recog. rate=40.678% Iteration=800/1000, recog. rate=42.3729% Iteration=1000/1000, recog. rate=42.3729% Iteration=200/1000, recog. rate=72.8814% Iteration=400/1000, recog. rate=93.2203% Iteration=600/1000, recog. rate=93.2203% Iteration=800/1000, recog. rate=94.9153% Iteration=1000/1000, recog. rate=94.9153% Iteration=200/1000, recog. rate=89.8305% Iteration=400/1000, recog. rate=86.4407% Iteration=600/1000, recog. rate=86.4407% Iteration=800/1000, recog. rate=86.4407% Iteration=1000/1000, recog. rate=88.1356% Elapsed time is 25.629392 seconds.
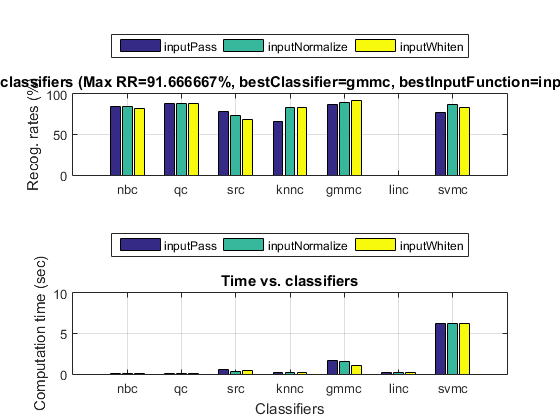
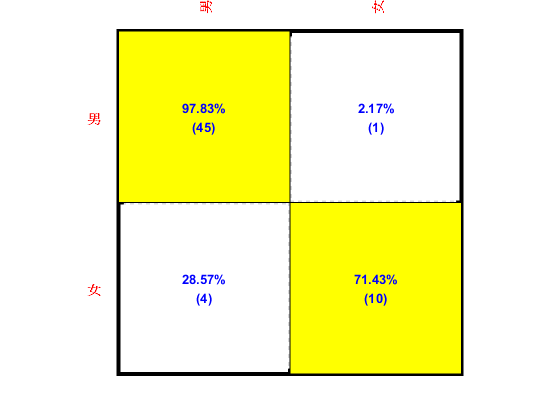
We can then display the confusion matrix of the best classifier:
confMat=confMatGet(ds.output, perfData(bestId).bestComputedClass);
opt=confMatPlot('defaultOpt');
opt.className=ds.outputName;
figure; confMatPlot(confMat, opt);
We can also list all the misclassified cases in a table:
%for i=1:length(imageData) % imageData(i).classIdPredicted=perfData(bestId).bestComputedClass(i); % imageData(i).classPredicted=ds.outputName{imageData(i).classIdPredicted}; %end %listOpt=mmDataList('defaultOpt'); %mmDataList(imageData, listOpt);
Summary
This is a brief tutorial on gender classification based on a person's attributes. There are several directions for further improvement:
- Explore feature combinations to improve the performance.
- Try any method for outlier identification to clean the dataset.
- Use other models for classification, such as deep neural networks.
Overall elapsed time:
toc(scriptStartTime)
Elapsed time is 42.338342 seconds.
Jyh-Shing Roger Jang, created on
date
ans = 05-Jan-2016