Part 1
- Convert a cell array to a structure array:
假設一異質陣列 A 的內容如下:
請寫一段程式碼 cell2structure01.m,可以將此異質陣列 A 轉成結構陣列 song,其中:張惠妹 聽海 1998 周華健 花心 1992 王 傑 一場遊戲一場夢 1988 孫燕姿 遇見 2003 孫燕姿 超快感 2000 F.I.R. Lydia 2004 蔡依林 愛情36計 2004 王心凌 明天見 2004 song(1).singer='張惠妹' song(1).name ='聽海' song(1).year ='1998' song(2).singer='周華健' ... 依此類推。 - 此題用到上題的結構陣列 song。請寫一段程式碼 structSort01.m,完成下列兩項工作:
- 請將結構陣列 song 的每筆資料依歌星名字內碼來排序,並將結果列印在螢幕。
- 請將結構陣列 song 的每筆資料依年代來排序,並將結果列印在螢幕。
- 此題用到上題的結構陣列 song。請寫一段程式碼 structCat01.m,完成下列兩項工作:
- 請取出所有歌星的名字,存成一個字串異質陣列,並將結果列印在螢幕。
- 請取出所有的年代,存成一個向量,並將結果列印在螢幕。
Part 2
- Create a structure array from a data file:
The contents of studentList.txt are shown next:
Note that in the table, there are two fields separated by the tab. The first field is "name" and the second field is "score". Please write a MATLAB script to read the file into a structure array "student" such that
- student(i).name: The name of the i-th student
- student(i).score: The scores of the i-th student, where each score is placed into a column vector for the student
- Plot field data in a structure array:
Given a structure array
studentobtained in the previous exercise, write a MATLAB script to plot the score curve of all the students. The figure should be like this:
If you do not have the result from the previous exercise, please run the following script to obtain the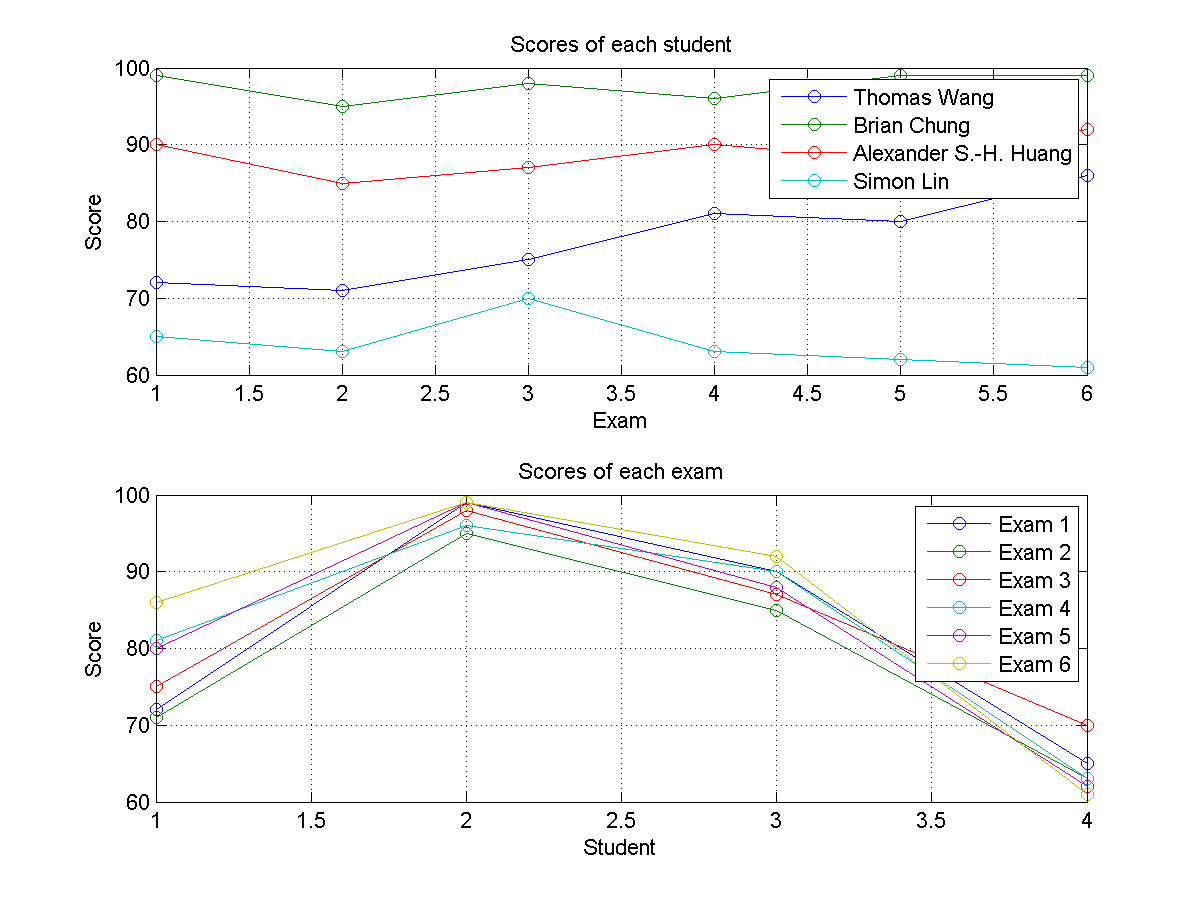
studentarray first: - Concatenate fields in a structure array:
Suppose a structure variable S is defined by the following statements:
clear S S(1) = struct('name', 'Banny', 'score', [85,80,92,78]); S(2) = struct('name', 'Joey', 'score', [80,85,90,88]); S(3) = struct('name', 'Betty', 'score', [88,82,90,80]); In particular, the field "score" stores the quiz scores for each of the student. Write a one-line MATLAB statement for each of the following tasks:- Compute the quiz average for each student.
- Compute the average score of all students for each quiz.
- Function for merging two structure variables:
Write a function myStructMerge.m to merge two structure variables of potentially different field names. The returned variable is a structure variable of field names equal to the union of the field names of the input structure variables. Example usage is as follows:
a.name='alex'; a.age=25; b.gender='male'; b.age=20; c=structCopy(a, b) The returned structure variable c is>> c c = name: 'alex' age: 20 gender: 'male' (Hint: You may want to use the function fieldnames().) - Function for concatenating two structure arrays:
Write a function myStructConcat.m to concatenate two structure arrays of potentially different field names. The returned variable is a column vector of structures which have the field names from both the input structure arrays. (Note that the input structure arrays must be converted into column vectors in order to concatenate them.) Example usage is as follows:
a.name='alex'; a.age=21; a(2).height=180; b.name='timmy'; b.gender='male'; c=myStructConcat(a, b) The returned column vector c have 3 elements:>> c(1) ans = name: 'alex' age: 21 height: [] gender: [] >> c(2) ans = name: [] age: [] height: 180 gender: [] >> c(3) ans = name: 'timmy' age: [] height: [] gender: 'male' (Hint: You may want to use the functions fieldnames() and setdiff().) - Sort a structure array:
A structure may be sorted by using different fields. Write a function structArraySort(structArray, fields) to sort a structure array based on the given fields. Note that "fields" is an cell array of field names, which is to be used as the keys for sorting. After sorting, Let fields = {$f_1$, $f_2$, ..., $f_n$}. A should be sorted based on the first element of fields. If field value is the same for field 1, then their corresponding values of field 2 should be sorted, and so on.
Hint: To achieve this goal, your program should sort the structure array based on $f_n$, $f_{n-1}$, ..., $f_2$, and $f_1$. - Function for ranking bigram counts:
Write a function bigramCountFun(str) to return a structure variable that contains the most frequent 3 bigrams of the given string, together with their counts. For instance, bigramCountFun(''吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮'') returns a bigram list with the following values:
- bigram(1).word='葡萄', bigram(1).count=4
- bigram(2).word='吃葡', bigram(2).count=2
- bigram(3).word='吐葡', bigram(3).count=2
- Find statistics of songs:
Given a song list stored as a strcuture array
songList (example mat file), write a function mySongStats.m with the following I/O format:[out1, out2]=mySongStats(songList);
whereout1 is a structure array which list the top-10 most productive artists (with field name "name") and their song counts (with field name "songCount"), sorted by "songCount" in a descending order). For artists who have the same number of songs, it should be listed based on the ascending dictionary order of the artist names.out2 is a cell string array which list the artists which has both Chinese and Taiwanese songs (sorted by the artist names).
- For both output, you need to remove items with artist names of "不詳", "unknown", and "老歌".
- If there is two artists playing duet for a song, they should be treated as a single independent artist. For instance, '江蕙、葉啟田' should be treated as an independent artist if there is such a situation in an entry.
- The sorting command "sort" in MATLAB is stable.
- Since your program needs to deal with Chinese, make sure it is stored in Big5 encoding. Our judge system will treat your file as in Big5 encoding for further processing. (If you are using MATLAB editor, everything should be ok. If you are using other editors, then you need to pay special attention to this.)
- Read an English dictionary:
- Write a MATLAB function to read the English dictionary english.wpa and return the result as a structure array "wpa", with 2 fields "word" and "pa" (phonetic alphabet, or PA for simplicity) . For instance:
- wpa(72561).word='multimedia'
- wpa(72561).pa{1}='m_ah_l_t_ay_m_iy_d_iy_ah'
- wpa(72561).pa{2}='m_ah_l_t_iy_m_iy_d_iy_ah'
- Find the top 5 mostly occurred beginning letters in English words and their counts.
- Find the top 5 mostly occurred PAs and their counts.
- Use "textread" to read the whole file into memory first to save time:
[word, pa]=textread(wpaFile, '%s\t%s'); Keep in mind that this is a big file with more than 120,000 entries! (If "textread" is not available, try "textscan".) - Use "cat" to put field values into an array.
- Use "split" (available in the Utility Toolbox) to split PA into a cell array. (Please use mode=0 to speed up the computation.)
- Use "join" (available in the Utility Toolbox) to join a string cell vector into a large string.
- Use "elementCount" (available in the Utility Toolbox) to count the elements in a vector.
- Write a MATLAB function to read the English dictionary english.wpa and return the result as a structure array "wpa", with 2 fields "word" and "pa" (phonetic alphabet, or PA for simplicity) . For instance:
- Bigram probability:
The probability of "given a word wi, the next word is wi+1" is denoted by P(wi+1|wi) = count(wiwi+1)/count(wi). Therefore for a given 5-word sentence Sw1w2w3w4w5E, the corresponding probability of this sentence can be approximated by the bigram probability:
P(S) P(w1|S) P(w2|w1) P(w3|w2) P(w4|w3) P(w5|w4) P(wE|w5) Based on the corpus of Tang's Poem, estimate the log probability of 「」 based on the bigram probability. -
Trigram probability:
The probability of "given a two-word sequence wiwi+1, the next word is wi+2" is denoted by P(wi+2|wiwi+1) = count(wiwi+1wi+2)/count(wiwi+1). Therefore for a given 5-word sentence Sw1w2w3w4w5E, the corresponding probability of this sentence can be approximated by the bigram probability:
P(Sw1w2) P(w3|w1w2) P(w4|w2w3) P(wE|w4w5) Based on the corpus of Tang's Poem, estimate the log probability of 「」 based on the bigram probability. -
Shannon visualization method:
We can use the bigram probability to generate Shannon visualization, as follows:
- Generate a random initial word by the probability P(S w1).
- Choose a random bigram w1w2 according to its probability.
- Keep selecting bigram unitl we choose E.
- String the words together to get the whole sentence.
S I ===> I want ===> want to ===> to eat ===> eat Chinese ===> Chinese food ===> food E So the whole sentence isS I want to eat Chinese food E Based on the corpus of Tang's Poem, generate the sentence of length 9 (start with 「黃」) with the maximum probability based on- the bigram probability.
- the trigram probability.
- the 4-gram probability.
MATLAB程式設計:入門篇
