- (**)
KNNC對於IRIS的分類效能對於代表點個數的變化:
請根據此範例,測試並畫出當 k-means 的分群數目(對每一個類別而言)由 1 增加到 20 時,辨識率的變化情形。
- 寫一段 MATLAB 程式 knncIrisRrVsClusterNum01.m,來顯示兩條曲線,包含訓練辨識率(inside test)及測試辨識率(outside test),畫出的圖形應該類似下圖:
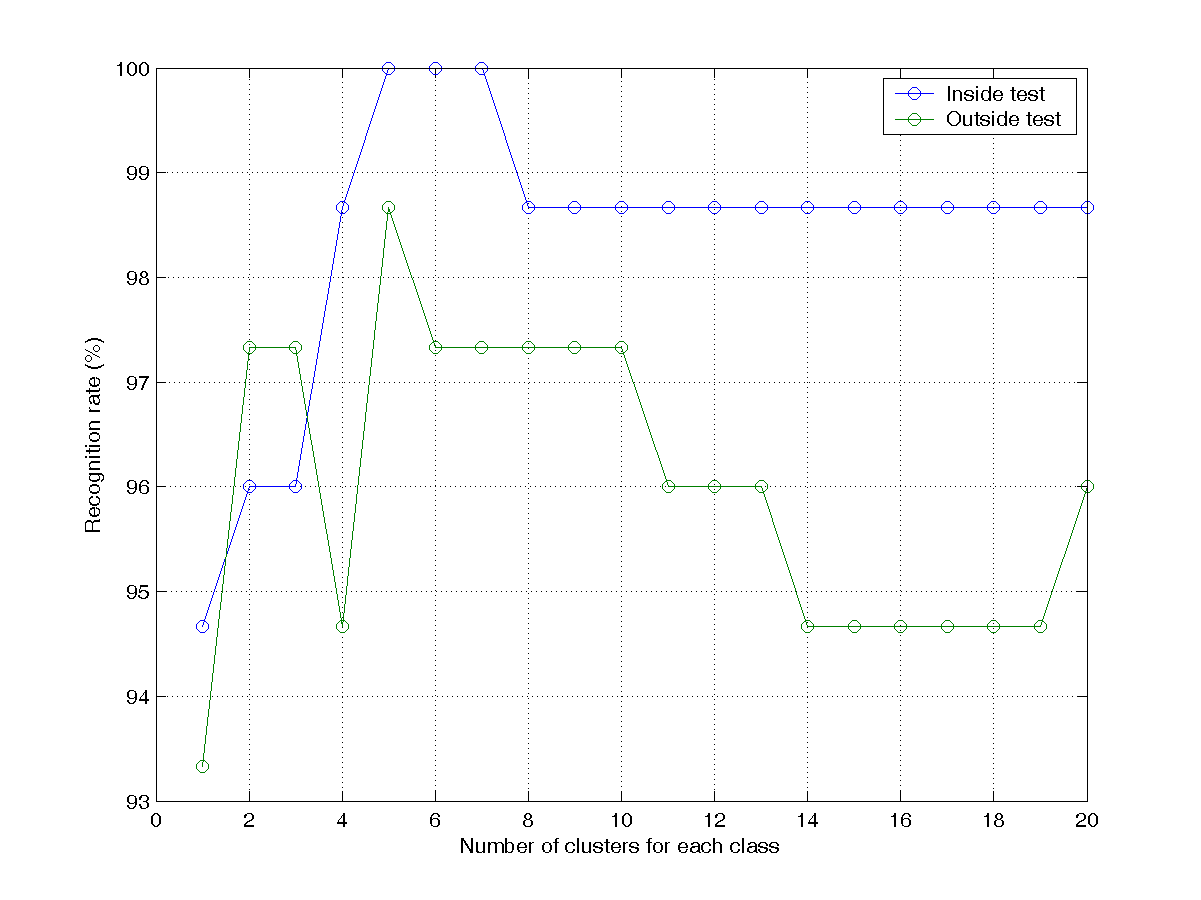
- 寫一段 MATLAB 程式 knncIrisRrVsClusterNum02.m,交換訓練資料及測試資料的角色,重畫一次辨識率的圖。畫出的圖形應該類似下圖:
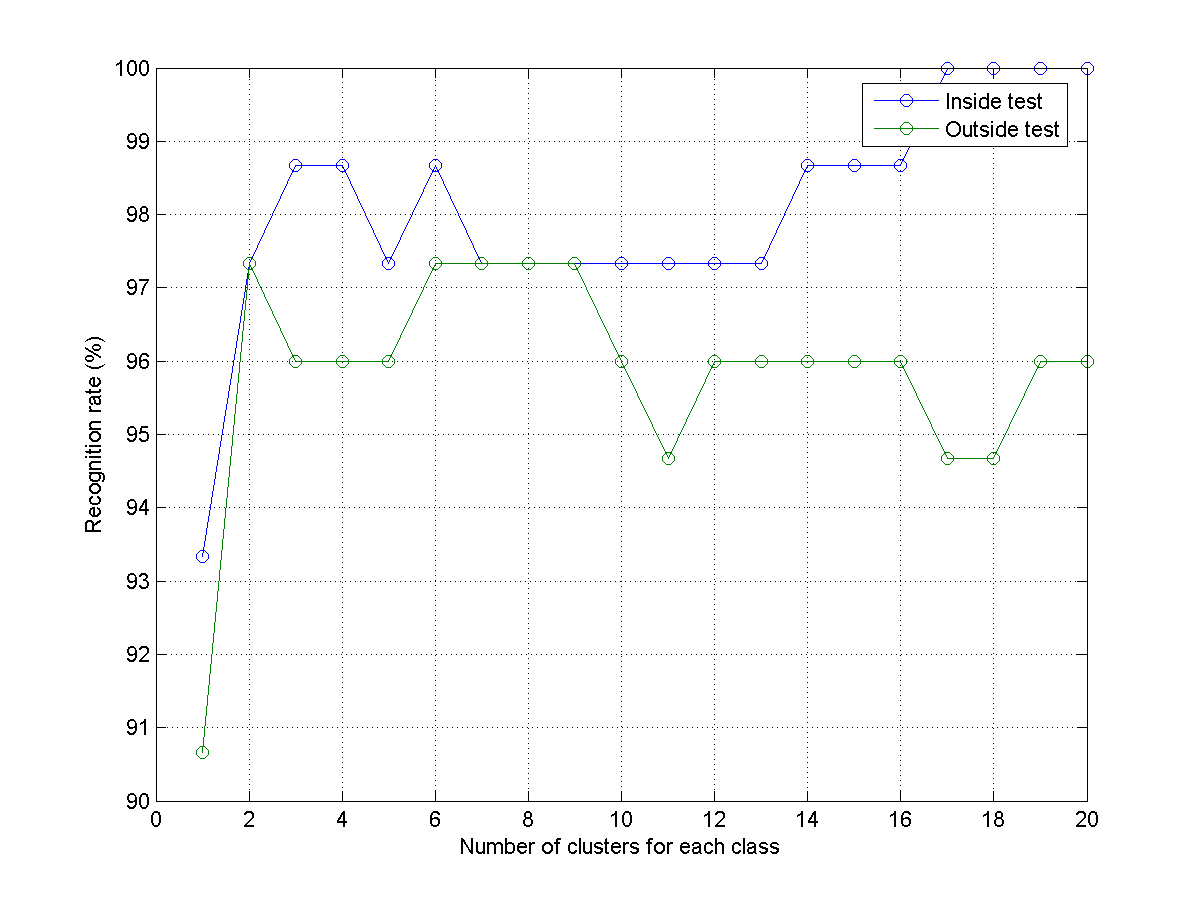
- 寫一段 MATLAB 程式 knncIrisRrVsClusterNum03.m,重複上兩題,畫出平均辨識率(上兩題的平均訓練辨識率和平均測試辨識率)的圖。畫出的圖形應該類似下圖:
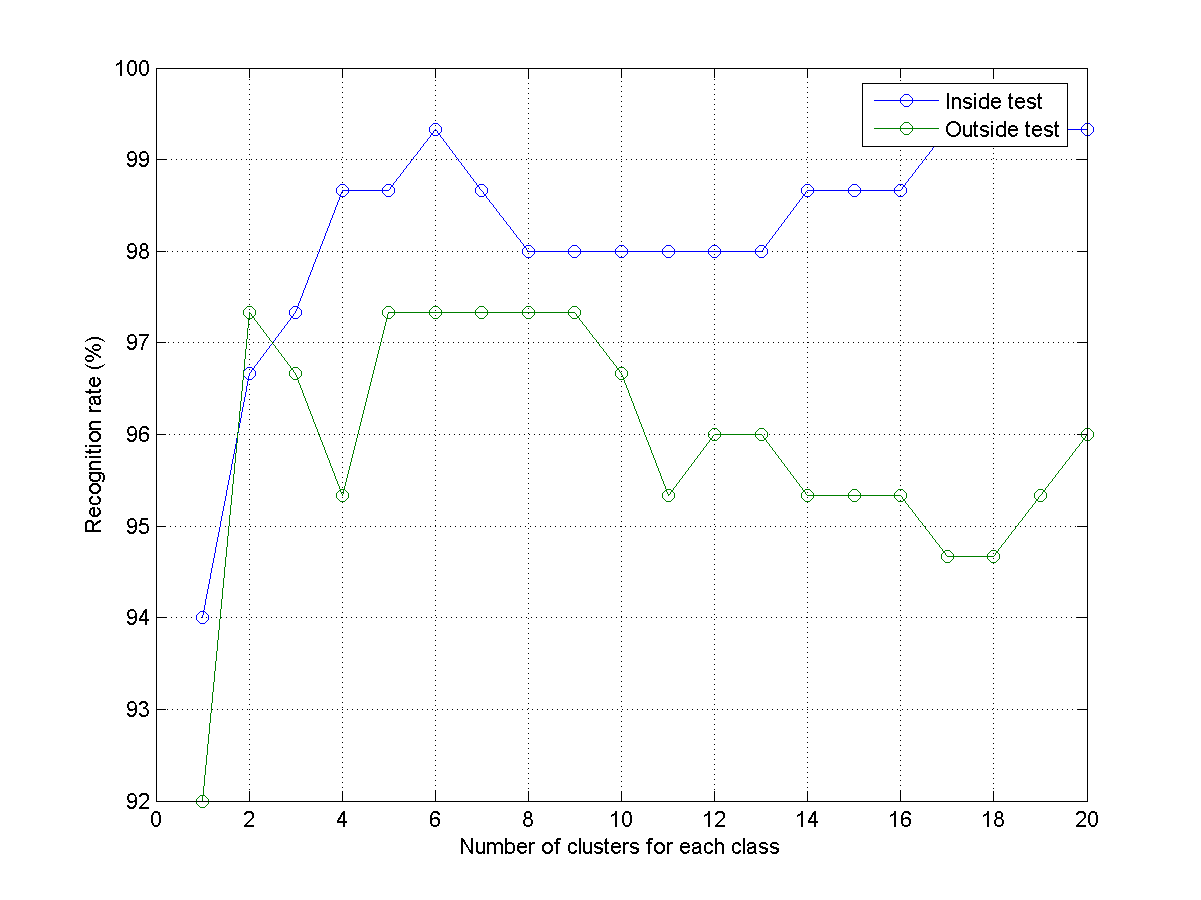
- 寫一段 MATLAB 程式 knncIrisRrVsClusterNum01.m,來顯示兩條曲線,包含訓練辨識率(inside test)及測試辨識率(outside test),畫出的圖形應該類似下圖:
- (**) KNNC對於WINE的分類效能對於代表點個數的變化: 請由 prData 指令來取得酒的分類資料,並重複前一題。
- (*)
酒的分類:
請由 prData 指令來取得酒的分類資料,並進行下列工作:
- 請使用「單一高斯分類器」來測試其辨識率。
- 請使用「線性分類器」來測試其辨識率。
- (*)
鮑魚年齡的辨識:
請由 prData 指令來取得鮑魚的分類資料,,此資料的輸出是鮑魚的年齡,我們以此年齡來代表類別,並進行下列工作:
- 請使用「單一高斯分類器」來測試其辨識率。
- 請使用「線性分類器」來測試其辨識率。
Data Clustering and Pattern Recognition (資料分群與樣式辨認)
