[english][all](請注意:中文版本並未隨英文版本同步更新!)
在不切音符的情況下,最簡單的辨識方法,就是線性伸縮(Linear Scaling),流程如下:
- 使用內差法,將使用者輸入的音高向量進行線性拉長或壓縮,例如伸縮比例可以是從 0.5 到 2.0,跳距是 0.1,共生出 16 個版本。
- 將這16個版本和資料庫中的每一首歌曲進行比對,得到16個距離,其中的最小值,即是輸入向量和此首歌的距離。
- 對所有資料庫歌曲進行比對,最短距離者,即是使用者所唱的歌。
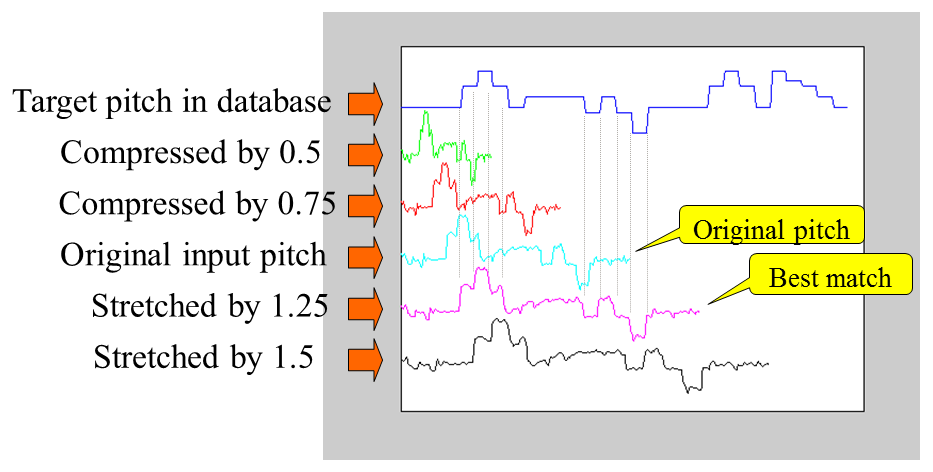
下面是一個線性伸縮的示意圖,共伸縮五次,當伸縮比例是 1.5 時,可以達到最佳的比對效果:
在實做上,還有下列細節要考慮:
- 內差法的選用:可以使用簡單的線性內差。
- 距離的選擇:通常我們使用 L1 norm,也就是計算每個對應元素絕對差值的和,或是使用 L2 norm,又稱為歐基理德距離,也就是計算每個對應元素差值的平方和,再開平方,但在實做上,我們通常只在比較距離的大小,因此常常省略開平方的動作,以節省計算。
- 距離的正規化:我們會將總距離除以點數,得到正規化的距離,以消除因伸縮造成點數不同所帶來的影響。
- 音高的校正:每一個人唱歌的key不同(通常女生的key比較高,男生的key比較低),因此在進行比對之前,要先進行校正。一般而言,校正的目的是要達到兩個向量之間距離的最小值,因此對於不同的距離計算方式,我們就有不同的校正法則:
- 若使用 L1 norm,我們可以採用「中位數校正」,亦即將輸入向量的中位數校正成對應資料庫向量的中位數。
- 若使用 L2 norm,我們可以採用「平均值校正」,亦即將輸入向量的平均值校正成對應資料庫向量的平均值。
- 對於休止符的處理:為了保持音符的特性,我們通常會將休止符(包含使用者的輸入和資料庫的歌曲)代換成前一個音。
線性伸縮用於旋律辨識的特性,可以說明如下:
- 如果使用者哼唱的歌聲不是忽快忽慢,那麼線性伸縮都可以達到不錯的辨識效果。
- 線性伸縮可以使用「一次到位」的音高校正,所以在計算上比較簡單。(相對而言,DTW 無法使用「一次到位」的音高校正,所以在計算上會比較繁複。)
以下是使用真實音高向量的範例:
下列範例採用兩種距離函數 L1-norm 和 L2-norm 來進行 LS,所得到的結果很接近:
Audio Signal Processing and Recognition (音訊處理與辨識)
