[english][all](請注意:中文版本並未隨英文版本同步更新!)
只要我們掌握了 DP 的遞迴原則,就可以根據需要,對 DTW 進行各種變形。在本節中,我們介紹另一種 DTW,其輸入格式具有下列特性:
- 使用者輸入:以音框為基礎的音高向量,不進行音符切割。(通常這類資料稱為 mid 格式。以我們進行的人工標示音高而言,每一點的時間長度是 256/8000 = 1/31.25 = 0.032 s = 32 ms。)
- 資料庫格式:以音符為比對單位,但只考慮音高。(通常這類資料稱為 note 格式,以向量 [音高, 音長, 音高, 音長...] 來表示。以我們哼唱選歌的資料而言,音長的單位都是 1/64 秒。)
假設使用者輸入的音高向量是 t 而標準答案的音符向量是 r,並假設 D(i, j) 是 t(1:i) 和 r(1:j) 之間的最短距離,則我們有下列遞迴式:
D(i, j) = min(D(i-1,j), D(i-1, j-1))+|t(i)-r(j)|
請見下列示意圖:
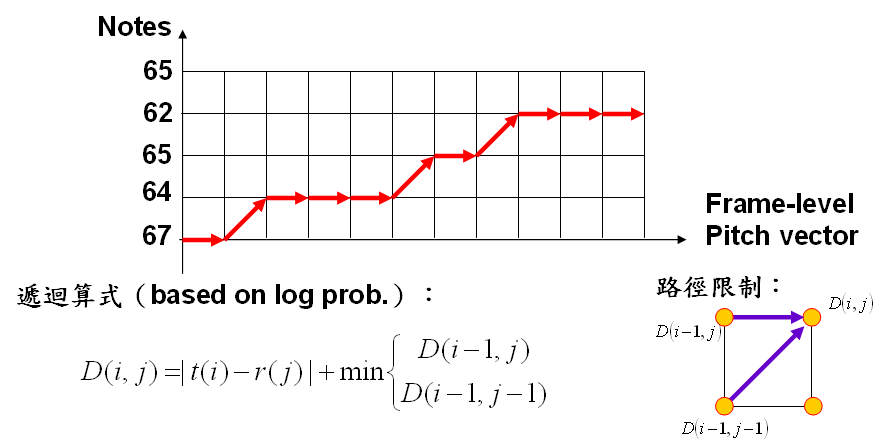
為便於說明,我們簡稱這一類方法為 type-3 DTW。此方法有下列特性:
- 由於資料庫格式是以音符為單位,所以計算量小於 type-1 及 type-2 DTW。
- 資料庫格式並沒有用到音符的音長資訊,所以理論上來說,辨識率應該低於 type-1 及 type-2 DTW。
- 無法進行一次到位的音高平移,這點和 type-1 及 type-2 DTW 是一樣的。
在以下的範例,我們使用 type-3 DTW 來進行音高向量對音符(只用音高)的「對位」(Alignment):
在上述範例中,我們在進行 dtw3 的比對前,做了兩件事情:
- 音調移位:我們假設歌唱者的速度和樂譜的速度是一樣的,因此我們將 note 先轉成 mid 格式,再取用和 PV 同樣的長度來計算其平均值為 noteMean,最後再將 PV 移到同樣的平均值。這是一個簡化的處理,因為我們並無法使用「一次到位」的音調移位。
- 休止符的處理:我們是把 PV 和 Note 中的休止符都砍掉來進行比對。這也是一個簡化的處理,後續會提到如何使用休止符來提高比對效果。
經過上述範例的對位後,我們可以將每個音高點所對應的音符音高畫出來,如下:
在上述範例中,由於綠色曲線(平移過的哼唱音高向量)和紅色曲線(由 dtw3 對位所產生的對應音符音高)的吻合程度並不理想,由此可以看出,我們的音調移位出了問題,所以得到的對位效果並不理想,很可能是由使用者哼唱的速度和樂譜的速度並不一致,這一首歌是「生日快樂」,我們可以直接試聽看看相關的檔案:
若要進行更吻合的對位,我們就必須改善音調移位。我們可以使用一個簡單的線性搜尋法(暴力法)來找到最佳的音高平移量,換句話說,也就是進行 81 次音調移位,平移量則平均分佈於 [-2, 2] 之間,請見下列範例:
由上述範例可以看出,type-3 DTW 對位的效果已經大幅改善,最短距離也大幅降低。相關檔案如下:
但是在上述範例中,我們還是可以發現對位的錯誤,例如在第一句「祝你生日快樂」的「樂」這個音符,只有被分配到三個音框,很明顯的過少。若要解決這個問題,有幾個可能的方向:
- 限制每一個音符所能分配的音框個數:例如每個音符所對應的音框總長度,不得小於音符長度的一半,也不得大於音符長度的兩倍。此規則的加入,使我們可以同時用到音符的音高及音長資訊。
- 使用休止符:在使用者哼唱的音高向量中,除了頭尾的休止符不算外,只要遇到一個休止區間,就代表一個舊音符的結束及新音符的開始,此規則可以適用到一般的哼唱選歌輸入。
我們可以修改 DTW 以符合上述規範,以便提高對位的準確度及旋律辨識的辨識率。
We can employ a modifed version of type-3 DTW which take rests into consideration, as follows:
Audio Signal Processing and Recognition (音訊處理與辨識)
