(請注意:中文版本並未隨英文版本同步更新!)
Slides for this chapter
如前一章所述,使用「觀察法」來算出音高,並不是太難,但是若要電腦自動算出音高,就需要對音訊進行進一步的自動分析。使用電腦對整段音訊進行抓取音高的過程,通常稱為「音高追蹤」(Pitch Tracking),所抓出來的音高資訊,有下列應用:
- 旋律辨識(Melody Recognition):或稱為「哼唱選歌」,也就是如何由使用者的哼唱,找出音樂資料庫中間對應的歌。
- 國語的聲調辨識(Tone Recognition):辨識使用者講一句話時,每一個字的聲調(一聲、二聲、三聲、四聲等)。
- 語音合成的韻律分析(Prosody Analysis)中的音高分析:如何在合成語音時,使用最自然的音高曲線。
- 語音評分中的音調評分(Intonation Assessment):如何評估使用者說話的語音,其音高曲線是否標準。
- 語音辨識(Speech Recognition):我們可以使用語句的音高來提高語音辨識的正確率。
總而言之,音高追蹤可說是音訊處理過程中,最基本也是最重要的一環,相關的研究,也進行了數十年,因此我們必須完全瞭解其原理,才能繼續進行其他相關的分析與處理。
音高追蹤的基本流程如下:
- 將整段音訊訊號切成音框(Frames),相鄰音框之間可以重疊。
- 算出每個音框所對應的音高。
- 排除不穩定的音高值。(可由音量來篩選,或由音高值的範圍來過濾。)
- 對整段音高進行平滑化,通常是使用「中位數濾波器」(Median Filters)。
在切音框的過程中,我們允許左右音框的重疊,因此我們定義「音框率」(Frame Rate)是每秒鐘所出現的音框個數,如果取樣頻率是 11025,音框長度是 256 點,重疊點數是 84,那麼音框率就是 11025/(256-84) = 64,換句話說,我們的電腦要能夠每秒鐘處理 64 個音框,才能達到「即時處理」的目的。示意圖如下:
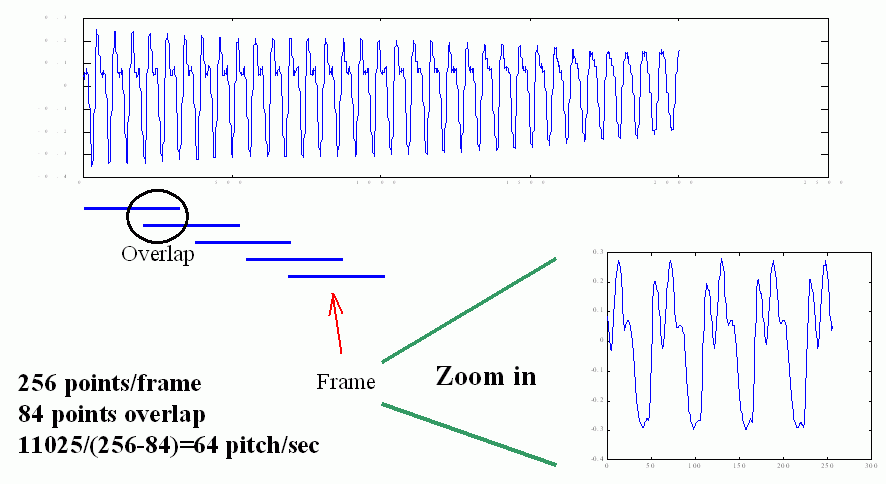
我們讓音框重疊的目地,只是希望相鄰音框之間的變化不會太大,使抓出來的音高曲線更具有連續性。但是在實際應用時,音框的重疊也不能太大,否則會造成計算量的過大。在選擇音框的大小時,有下列考量因素:
- 音框長度至少必須包含 2 個基本週期以上,才能顯示語音的特性。已知人聲的音高範圍大約在 50 Hz 至 1000 Hz 之間,因此對於一個的取樣頻率,我們就可以計算出音框長度的最小值。例如,若取樣頻率 fs = 8000 Hz,那麼當音高 f = 50 Hz(例如男低音的歌聲)時,每個基本週期的點數是 fs/f = 8000/50 = 160,因此音框必須至少是 320 點;若音高是 1000 Hz(例如女高音的歌聲)時,每個基本週期的點數是 8000/1000 = 8,因此音框必須至少是 16 點。
- 音框長度也不能太大,太長的音框無法抓到音訊的特性隨時間而變化的細微現象,同時計算量也會變大。
- 音框之間的重疊完全是看電腦的運算能力來決定,若重疊多,音框率就會變大,計算量就跟著變大。若重疊少(甚至可以不重疊或跳點),音框率就會變小,計算量也跟著變小。
由一個音框計算出音高的方法很多,可以分為時域和頻域兩大類:
- 時域(Time Domain)
- ACF: Autocorrelation function
- AMDF: Average magnitude difference function
- SIFT: Simple inverse filter tracking
- 頻域(Frequency Domain)
- Harmonic product spectrum method
- Cepstrum method
這些方法將在以下各小節介紹。
Audio Signal Processing and Recognition (音訊處理與辨識)
