- 聲學模型(Acoustic Model,或簡稱 Model):使用於 HMM 的一個抽象單位,通常一個聲學模型包含數個狀態。我們可以使用音節或是音素作為一個聲學模型。
- 音節(Syllables):完整發音的單位,以中文來說,一個字元對應一個音節;以英文來說,一個詞彙可以對應到數個音節,例如 tomorrow 有三個音節。
- 音素(Phoneme):或簡稱 Phone,是發音的最小單位,例如「大」的發音可以拆解成ㄉ和ㄚ兩個音素,但是音素的拆解並非一成不變,例如碰到滑母音,我們通常就會將一個注音符號拆成兩個音素,例如ㄞ、ㄟ、ㄠ、ㄡ等,這幾個母音在發音過程中,都會呈現連續的變化。
- Monophone:以單一音素作為一個聲學模型,例如ㄇ。
- Biphone:以連續兩個音素作為聲學模型,通常是 RCD (Right-context dependent),例如將ㄇ出現於ㄇ-ㄚ和ㄇ-ㄧ視為兩個不同的聲學模型。
- Triphone:以連續三個音素作為聲學模型,例如將ㄨ在ㄎ+ㄨ-ㄢ及ㄍ+ㄨ-ㄤ視為兩個不同的聲學模型。
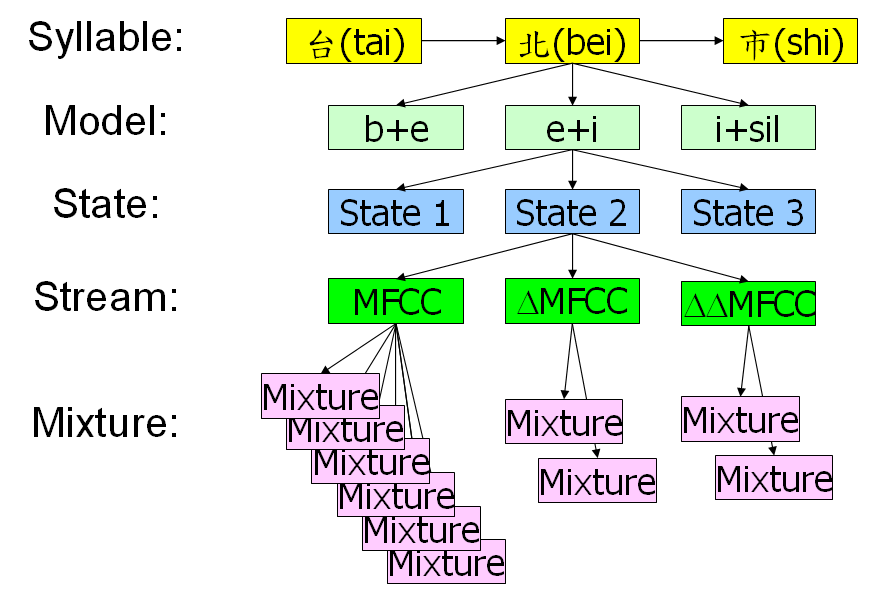
若以辨識網路及 HMM 的觀點來看,示意圖如下:
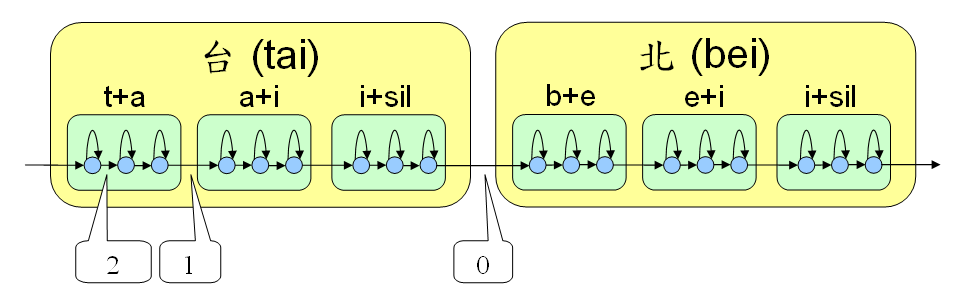
- Type 0: Transition between syllable
- Type 1: Transition between model
- Type 2: Transition between state
Audio Signal Processing and Recognition (音訊處理與辨識)
