讓電腦能夠聽懂人的對話,一直是人類長久以來的夢想。近年來由於電腦速度的提升,語音辨識的應用也越來越普遍,例如智慧型手機的語音應用(如蘋果手機的 Siri 語音助理 或是安卓手機的語音轉文字)、智慧音箱(如 Amazon Alexa、Google Home)等,都是深入人們日常生活的語音辨識實際應用。
語音辨識的應用,可以根據不同的方式來分類。第一種方式,是根據語音辨識系統的使用者來分類:
- 語者相關(speaker dependent):系統的使用者只限定特定人士。
- 語者獨立(speaker independent):系統的使用者可以通用於一般人士。
第二種方式,是根據語音辨識系統的功能來分類,依照難度來區分,可以列出如下::
- 語音命令(voice command):使用者下達一句語音命令,系統從有限命令集中找出最有可能的命令,並執行相關動作。
- 關鍵詞偵測(keyword spotting):使用者下達一句語音(例如「請幫我查詢今天天氣如何」),系統可以偵測這一句語音是否含有特定的內容(如「今天」及「天氣」)。
- 聽寫(dictation):使用者下達一段語音(例如一段新聞播報),系統可以自動產生正確逐字稿,例如 youtube 的字幕產生系統。
- 對話(dialog):使用者可以直接和電腦對話,電腦收到一段語音後,能夠瞭解使用者的意圖(intention),並以語音或文字進行合理且正確的回覆。一般的語音聊天機器人(chatbot),就是屬於這種系統。
在建立語音辨識系統之前,我們必須先從語音訊號中切出音框,然後從音框中抽出跟音色相關的特徵,期中最常用的特徵就是 MFCC,這是一個在語音辨識最常用到的特徵,每一個音框通常可以抽出 13、26 或 39 維的 MFCC 向量,這方面的說明或計算代碼,都可以由網路上查到。
根據上面的分類,最簡單的語音辨識系統,就是「語者相關的語音命令辨識系統」,通常就是「用自己的聲音比對自己的聲音」,例如早期的手機(如 Sony Ericson T18),你可以預錄幾組語音,每一個語音對應到一組電話號碼,例如「拉麵」對應到拉麵店的電話,因此當你對手機喊「拉麵」時,系統會對你輸入的聲音以及已經預錄好的聲音進行比對,若比對正確,手機就會自行撥電話到拉麵店。(但是,對電腦而言,人類的語音變化度極大,若是金城武的妹妹對金城武的手機喊「拉麵」,不見得有效,因為內部用來比對的錄音是金城武的聲音,而不是他妹妹的聲音。)
若要建立「語者相關的語音命令辨識」系統,最基本的方法,就是使用動態時間扭曲(dynamic time warping, DTW)來進行比對,這是一個基於動態規劃(dynamic programming, DP)的方法,它可以根據講話的音色來進行比對,同時也會針對不同的語音速度來進行局部伸縮,以達到最好的對位(alignment)效果,示意圖如下。
|
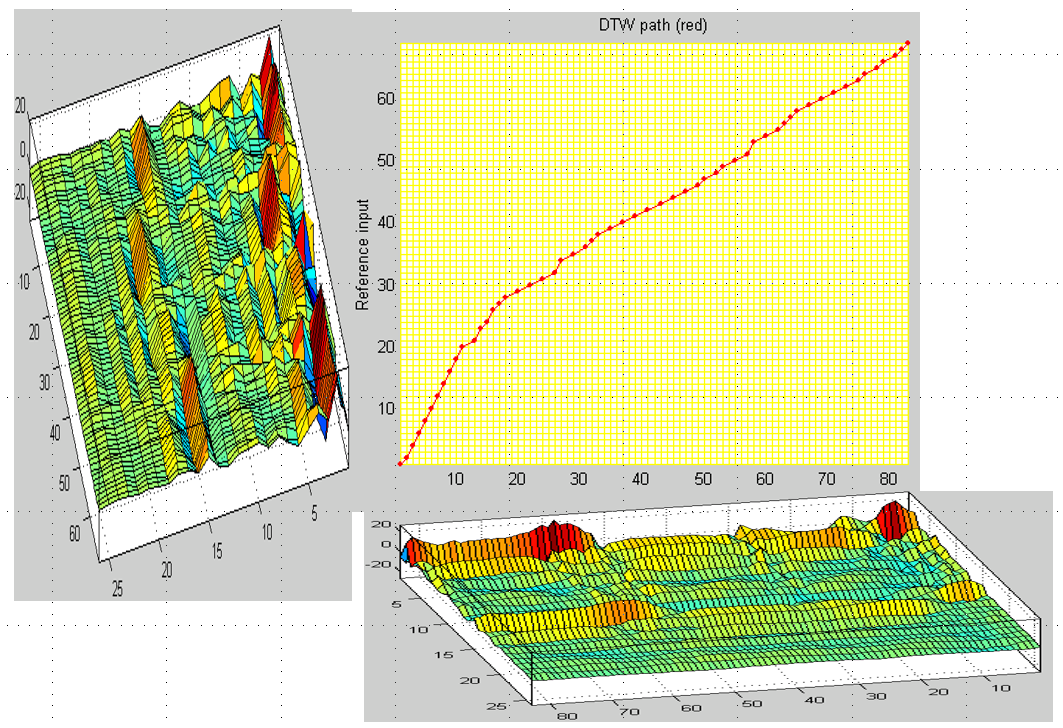
以上述範例而言,在X軸和Y軸的語音內容都是「清華大學」,但是Y軸的語音比較平穩,X軸的語音則是前面快後面慢,經由 DTW 的對位,可以找到兩者最佳的對位,進而求出兩段語音的最短距離。因此,若要建立一個「語者相關的語音命令辨識系統」,只要請使用者先預錄一組語音命令(每一個語音命令可以錄製多次,例如三次),當使用者發出測試語音時,就可以進行端點偵測(endpoint detection)並計算 MFCC,最後拿這一組 MFCC 和預錄語音命令的 MFCC 來進行 DTW 比對,距離最短的的語音命令,就是我們要找的答案。
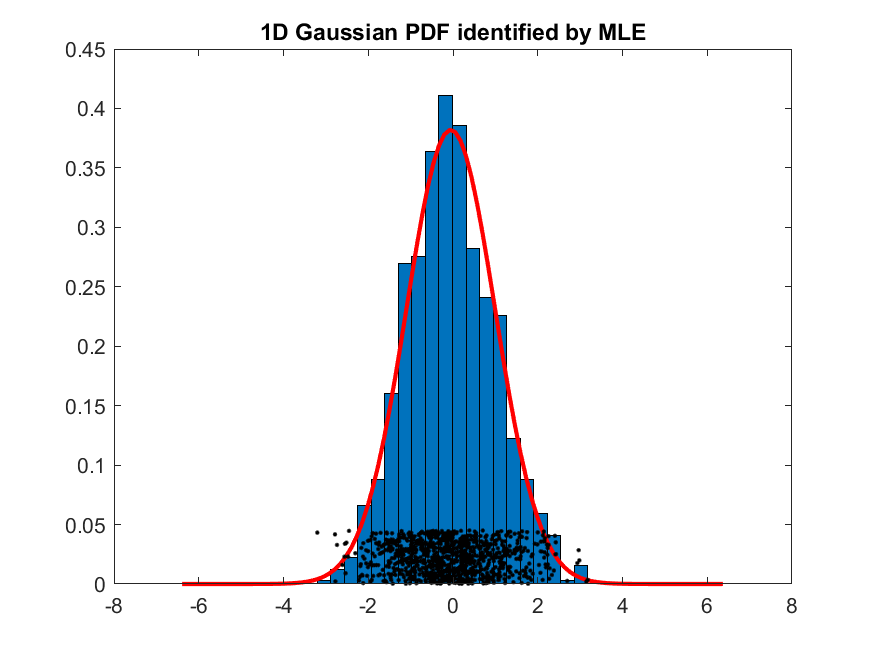
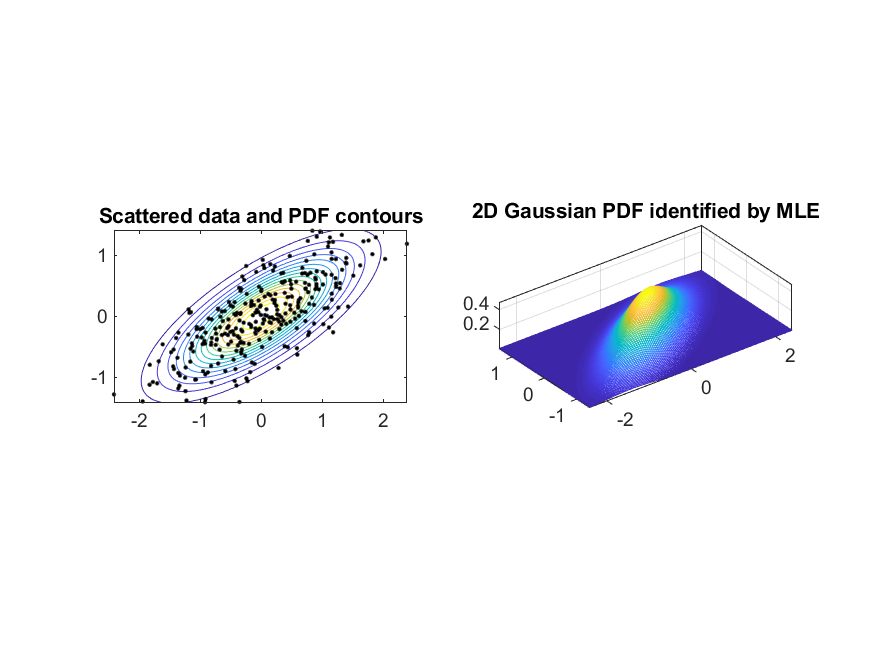
而最複雜的語音辨識系統,就是「語者無關的對話系統」,例如蘋果手機的 Siri 語音助理、亞馬遜的 Alexa 智慧音箱,以及 Google Home 語音助理,這些系統就像是虛擬助理般,都可以和人們進行簡單的對話,同時藉由瞭解使用者的意圖,幫忙人們做一些簡單事情,如預定車票、查詢天氣或電影等。若要建構此類系統,那就要改用比較複雜的聲學模型來進行,語音的特徵還是 MFCC,但是我們要使用不同的聲學模型來代表不同的音色(子音或母音等),並根據此聲學模型來算出一個MFCC向量所對應的機率密度(probability density)。舉例來說,我們可以收集 100 人所發出的母音「ㄚ」,切出來音框後,每一個音框再抽抽出 39 維的 MFCC 向量,再使用一個高維度的機率密度函數(probability density function, PDF)來建立這些 MFCC 向量的聲學模型,而建立此模型最常用的方法就是最大似然率估測法(maximum likelihood estimate, MLE)。一般最常用的 PDF 是 GMM (Gaussian mixture models),是由一組高斯機率密度函數(Gaussian PDF)的加權平均所組成,根據最大似然率估測法,我們就可以根據所給的一組 MFCC 向量來計算 GMM 的最佳參數值,包含每一個高斯機率密度函數的平均向量(mean vector)和共變異矩陣(covariance matrix),以及這些函數的加權權重(weighting factors)。
以下是使用高斯 PDF 及 GMM PDF 來對 1-D 資料進行建模的典型範例:
|
|
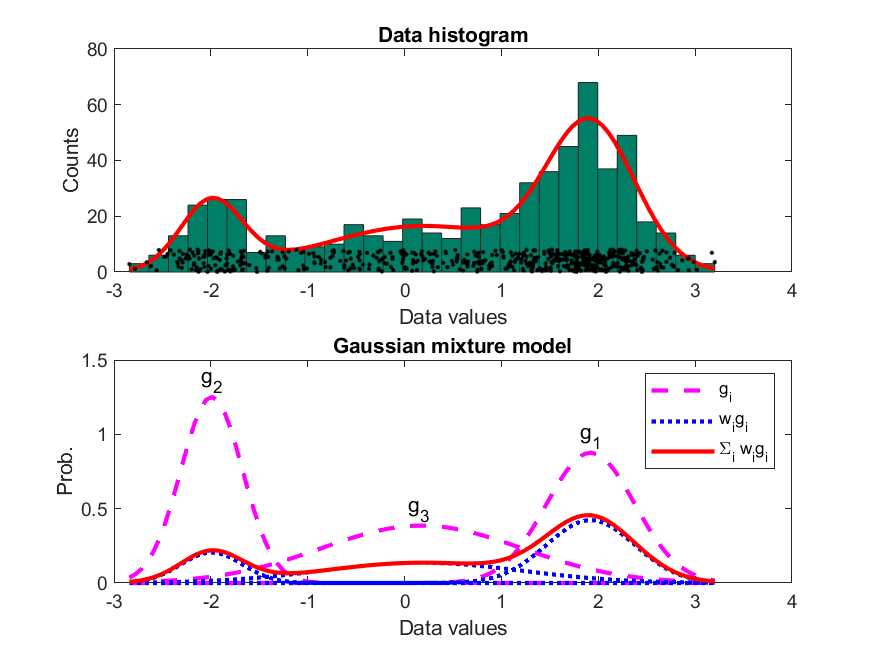
以下是使用高斯 PDF 及 GMM PDF 來對 2-D 資料進行建模的典型範例:
|
|
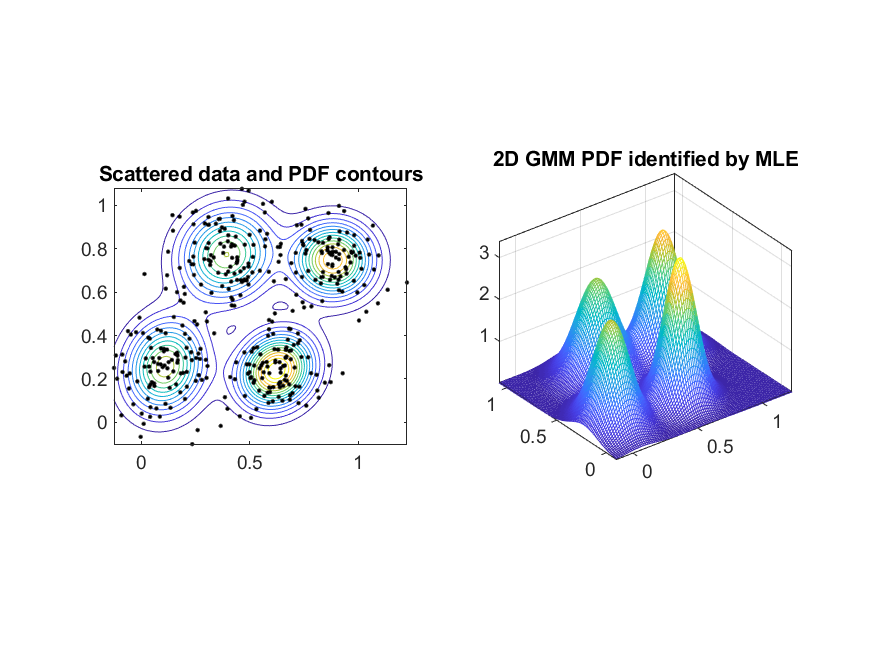
依照 MLE 的方法,我們也可以對 39-D 的 MFCC 來進行建模,只不過是我們很難用簡單的曲面圖或等高線來檢視建模之後的結果。
使用 GMM 來建立聲學模型,還是一個比較基本的方法。如果我們考慮發音隨時間而變的情況,那麼使用一個單一的PDF來建立聲學模型是不合理的。例如母音「ㄞ」在發音的過程中,我們的嘴形是連續變化的,基本上是由「ㄚ」變到「ㄧ」,因此若要建立更精準的聲學模型,我們可以改用HMM(hidden Markov models),這是一個用於描述序列(sequences)的機率密度函數,每一個HMM由數個狀態(state)所組成,每一個狀態就是一個靜態的PDF,而狀態之間的轉移可以由轉移機率(transition probability)來表示。以下是一個具有三個狀態的HMM模型的示意圖:
|
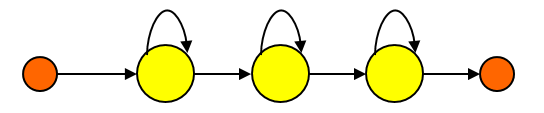
- 對於每一個語句,使用DP來將語句的MFCC向量分配到每一個狀態。
- 對於每一個狀態,根據被分派到的所有MFCC向量來計算對應的GMM最佳參數。
- 根據每一個音框所被分配到的狀態,來計算轉移機率矩陣。
- 跳回步驟一,直到所有的參數收斂。
使用HMM來表示一個聲學模型,通常得到的效果會更好,因為它能夠表示一個發音隨時間而變化的現象。
在實際辨識系統中,我們通常會更仔細地將所有發音區分為更基本的基本發音單位,稱為音素(phoeme),這是人類語音中,能夠區別不同發音的最小聲音單位,因此我們會根據音素來建立聲學模型,而不是單以注音符號中的子音或母音來建立模型。例如:
- 「ㄚ」可以使用一個音素來表示:a
- 「ㄞ」可以使用兩個音素來表示:a 和 i(也就是「ㄚ」和「ㄧ」的串接)
- 「ㄠ」可以使用兩個音素來表示:a 和 u(也就是「ㄚ」和「ㄨ」的串接)
此外,為了能夠更精準地抓出不同的發音,我們會將音素再細分各種情況來進行聲學模型的建模,以「平安」(ㄆㄧㄥ-ㄢ 或 ping-an)為例:
- monophone:以單音素來建立聲學模型,可得到 p-i-ng-a-n
- biphone:以右相關(right-content dependent, RCD)音素來建立聲學模型,可得到 sil+p, p+i, i+ng, ng+a, a+n, n+sil。(sil代表silence。)
- triphone:以左右相關音素來建立聲學模型,可得到 sil+p-i, p+i-ng, i+ng-a, ng+a-n, a+n-sil。
因此,對於一句文句,我們可以先轉出拼音,然後根據拼音轉出音素序列,然後就可以將音素序列再轉換成HMM聲學模型的串接。若以文句「你好」來說明,建立biphone sequence(不考慮 leading silence)的步驟如下:
- 轉拼音:你好 ==> ㄋㄧ-ㄏㄠ 或 ni-hao
- 轉音素:ㄋㄧ-ㄏㄠ 或 ni-hao ==> n_i-h_a_u
- 轉biphone: n+i, i+h, h+a, a+u, u+sil
- 串接成HMM模型,如下:
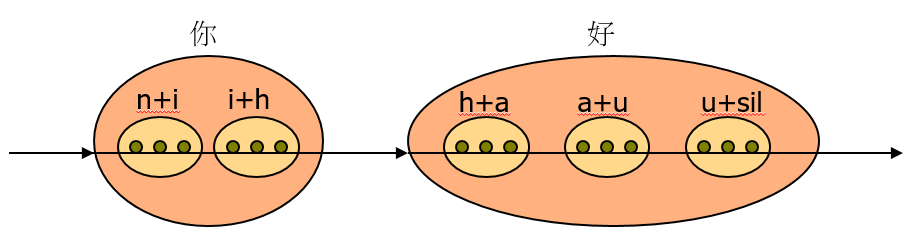
圖 5.:對應到「你好」的 HMM 模型示意圖。
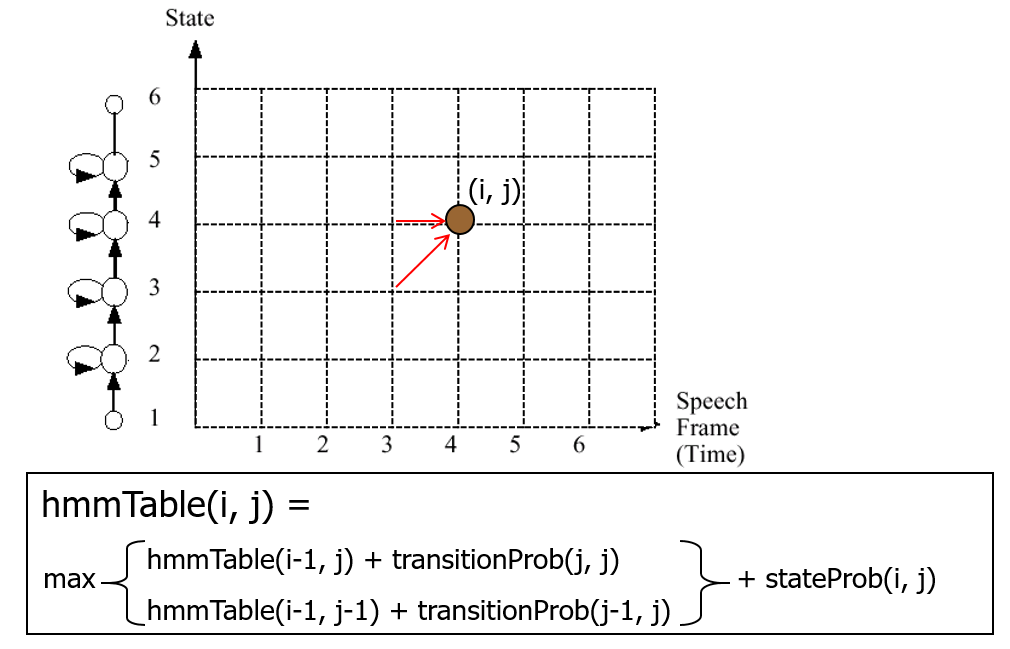
針對一句語音,我們可以先算出對應的MFCC向量組,然後就可以將這個向量組送到這個串接的聲學模型,使用 Viterbi search (這也是一種DP的方法)來得到這個語音對於這個HMM的最大似然率,我們可以想像這個過程類似在填表,當我們完成填表,就可以知道每個音框要分配到哪一個狀態,才能得到似然率的最大值,圖形說明如下:
|
如果我們更進一步想進行更複雜的「聽寫」,那就要考慮到每個人講話時,到底會用到哪一些詞,以及這些詞在串接時的可能性。用來計算這些可能性的數學模型稱為「語言模型」(language model),和之前所說明的聲學模型剛好在語音辨識扮演相輔相成的角色。一般的語言模型是以 n-gram 模型為主,n-gram 就是n個詞的串接,因此簡單地說,一個模型可以計算一組詞串接在一起的機率。以英文為例,若一句語音被辨識成兩種可能:
- It's hard to recognize speech.
- It's hard to wreck a nice beach.
|
上述使用HMM的方法,已經被用了數十年,但是近期流行的DNN(deep neural networks)方法,所的到的辨識效果更好,但是需要的計算量更大,其基本概念是使用DNN來取代GMM(因此原來的GMM-HMM的架構就被取代成 DNN-HMM),並使用GPU來進行大量的優化運算,所以才能得到更好的辨識效果。
Audio Signal Processing and Recognition (音訊處理與辨識)
