To implement CHMM, usually we rely on HTK (Hidden Markov Model Toolket) for corpus preparation and training. In this section, we shall use a simple example to demonstrate the use of HTK. In this example, we want to construct CHMM for the recognition for the digits from 0 to 9 in Mandarin. You will be able to know how to do corpus training, and how to compute the recognition rates.
In this homepage, we intend to display files of several extensions (mlf, scp, template, cfg, pam, init, hmm, net, grammar, etc) via iframe tags in the web browser directly. To this end, you need to cancel the application associations for these extensions. (Otherwise there will be popup windows to ask if you want to download the files, etc.) You can use the following batch file to cancel the extension-application associations:
Please run the above batch file under the DOS prompt. Then you can reload this homepage such that all files can be displayed on within iframe tages in this page correctly.
Before move on, you need to download the following files for this section:
- HTK commands: After decompression, there are two directories "bin.win32" and "bin", which contain HTK commands and other data-processing commands, respectively. You need to add these two directories to the system's search path via 「控制台/系統/進階/環境變數/系統變數」. If the decompressed directory is put as c:\htk, then you can also append the search path with the DOS window as follows:
set path=%path%;c:\htk\bin.win32;c:\htk\bin - Corpus and training scripts: There are two directories:
- training: Training scripts.
- waveFile: Corpus of digits 0 ~ 9 in Mandarin.
Before start our corpus training, we need to prepare two files manually. The first file is "digitSyl.pam" which specifies how to decompose the phonetic alphabets of each digit into the corresponding acoustic models. For simplicity, our current approach use each syllable as an acoustic model, as follows:
The above decomposition is a rough but simple way to define syllable-based acoustic models for this application. More delicate decompositions based on monophones or biphones will be explained later.
The second file is digitSyl.mlf, which define the contents (in the form of acoustic models) of each utterance, as follows:
In the above file, we use sil for silence. We add leading and trailing sil around ling to indicate the utterance of "0" is surrounded by silence.
In the following, we shall explain the contents of the MATLAB script goSyl13.m and the DOS batch file goSyl13.bat. Both these files involve three major tasks:
- Extraction of acoustic features of MFCC.
- Corpus training based on EM to find the optimum parameters.
- Performance evaluation based on recognition rate.
- Acoustic feature extraction of MFCC
- Create output directories
We need to create 3 directories for holding output files:- output: For various intermediate output files
- output\feature: For feature files of all utterances.
- output\hmm: For HMM parameters during training
mkdir('output'); mkdir('output/feature'); mkdir('output/hmm');The batch command is:for %%i in (output output\feature output\hmm) do mkdir %%i > nul 2>&1
If the directories exist, the batch command will not display any warning messages. - Generate digitSyl.mnl and digitSylPhone.mlf
The MATLAB comand for generating syl2phone.scp is:fid=fopen('output\syl2phone.scp', 'w'); fprintf(fid, 'EX'); fclose(fid); The corresponding batch command is:@echo EX > output\syl2phone.scp The contents of syl2phone.scp are shown next:The string "EX" represents "expand", which serves to expand syllables into acoustic models to be used with the HTK command "HLED". This command is used to generate digitSyl.mnl and digitSylPhone.mlf, as shown next:
HLEd -n output\digitSyl.mnl -d digitSyl.pam -l * -i output\digitSylPhone.mlf output\syl2phone.scp digitSyl.mlf
In the above expression, input files are in blue while output files are in red. The output file digitSyl.mnl lists all the used acoustic models:The file digitSylPhone.mlf contains the results of converting the syllable information in digitSyl.mlf into acoustic models for corpus training, as follows:
In this example, since we are using syllable-based acoustic models, the contents of digitSylPhone.mlf are the same as those in digitSyl.mlf.
- Generate wav2fea.scp
Before extracting acoustic features, we need to specify the file mapping between each utterance (with extension .wav) and its corresponding feature file (with extension .fea). This mapping is specified in the file wav2fea.scp, which can be generated by the following MATLAB commands:wavDir='..\waveFile'; waveFiles=recursiveFileList(wavDir, 'wav'); outFile='output\wav2fea.scp'; fid=fopen(outFile, 'w'); for i=1:length(waveFiles) wavePath=strrep(waveFiles(i).path, '/', '\'); [a,b,c,d]=fileparts(wavePath); fprintf(fid, '%s\t%s\r\n', wavePath, ['output\feature\', b, '.fea']); end fclose(fid);
The corresponding batch command is much simpler:(for /f "delims=" %%i in ('dir/s/b wave\*.wav') do @echo %%i output\feature\%%~ni.fea)> output\wav2fea.scpThe contents of wav2fea.scp are shown next:From the contents of wave2fea.scp, we know that all the feature files will be put under "output\feature" with a file extension of "fea".
- Use HCopy.exe for acoustic feature extraction
Now we can use HTK command "HCopy" to generate MFCC feature files for all utterances:HCopy -C mfcc13.cfg -S output\wav2fea.scp
In the above expression, mfcc13.cfg is a configuration file which specifies parameters for generating MFCC, with the following contents:The meanings of these parameters can be found in the HTK manual.
- Create output directories
- Corpus training based on EM to find the optimum parameters
- Generate file lists in trainFea.scp and testFea.scp
We need to generate file lists for training and test sets, with the following MATLAB commands:outFile='output\trainFea.scp'; fid=fopen(outFile, 'w'); for i=1:460 wavePath=strrep(waveFiles(i).path, '/', '\'); [a,b,c,d]=fileparts(wavePath); fprintf(fid, '%s\r\n', ['output\feature\', b, '.fea']); end fclose(fid); outFile='output\testFea.scp'; fid=fopen(outFile, 'w'); for i=461:length(waveFiles) wavePath=strrep(waveFiles(i).path, '/', '\'); [a,b,c,d]=fileparts(wavePath); fprintf(fid, '%s\r\n', ['output\feature\', b, '.fea']); end fclose(fid);
From the above program, it is obvious that the first 460 files are for training, while all the others are for test. The corresponding batch commands are:for %%i in (train test) do ( for /f %%j in (%%i.list) do @echo output\feature\%%j.fea ) > output\%%iFea.scp
Note that the above code segment read contents from files train.list and test.list (which are prepared in advance), and generates files trainFea.scp and testFea.scp for corpus training and recognition rate computation, respectively. The contents of trainFea.scp are: - Generate HMM template file
For corpus training, we need to generate an HMM template file to specify the model structure, such as how many states in an acoustic model, how many streams in a state, and how many Gaussian components in a stream, and so on. The HTK command is:outMacro.exe P D 3 1 MFCC_E 13 > output\template.hmm
where- P: HMM system type, which is fixed to "P" for the time being.
- D: Types of the covariance matrix, which could be "InvDiagC", "DiagC", or "FullC". The "D" is the above command represents "DiagC", which is the most commonly used setting.
- 3: Number of states for a model
- 1: Indicate each state has 1 stream with 1 Gaussian component. (For example, "5 3" indicates there are 2 streams in a state, with 5 and 3 Gaussian components, respectively.)
- MFCC_E: The acoustic parameters are MFCC and energy.
- 13: Dimension of the feature vector.
feaType='MFCC_E'; feaDim=13; outFile='output\template.hmm'; stateNum=3; mixtureNum=[1]; streamWidth=[13]; genTemplateHmmFile(feaType, feaDim, stateNum, outFile, mixtureNum, streamWidth);
The generated template.hmm specifies an HMM of 3 states, with 1 stream per state, and 1 component per stream, with the following contents:Since this file is used to specify the structure of HMM, all the parameters are given preset reasonable values. Moreover, the states are given indices from 2 to 4 since the first and last states are dummy in HTK convention.
- Populate HMM template using all corpus
In the next step, we need to compute the initial HMM parameters from the corpus and put them into template.hmm to generate output\hcompv.hmm. By doing so, we can have a set of parameters (for a single HMM of 3 states) which is a better guess than the preset value in template.hmm. Later on, we should copy the parameters to all of the HMMs for EM training. The following command can populate output\template.hmm to generate output\hcompv.hmm:HCompV -m -o hcompv.hmm -M output -I output\digitSylPhone.mlf -S output\trainFea.scp output\template.hmm
The contents of the generated output\hcompv.hmm are:From the contents of output/hcompv.htmm, it can be observed that:
- The transition probabilities are not changed.
- The mean and variance of each Gaussian have been changed to the same values for all components. These values are obtained via MLE (maximum likelihood estimate) based on all corpus.
- Copy the contents of hcompv.hmm to generate macro.init
In this step, we need to copy the contents of hcompv.hmm to each acoustic model, with the following MATLAB commands:% Read digitSyl.mnl modelListFile='output\digitSyl.mnl'; models = textread(modelListFile,'%s','delimiter','\n','whitespace',''); % Read hcompv.hmm hmmFile='output\hcompv.hmm'; fid=fopen(hmmFile, 'r'); contents=fread(fid, inf, 'char'); contents=char(contents'); fclose(fid); % Write macro.init outFile='output\macro.init'; fid=fopen(outFile, 'w'); source='~h "hcompv.hmm"'; for i=1:length(models) target=sprintf('~h "%s"', models{i}); x=strrep(contents, source, target); fprintf(fid, '%s', x); end fclose(fid);The corresponding DOS batch commands are:(for /f %%i in (output\digitSyl.mnl) do @sed 's/hcompv.hmm/%%i/g' output\hcompv.hmm) > output\macro.init
The generated HMM parameter file is macro.init, with the following contents:This file contains the HMM parameters of 11 (sil、ling、i、er、san、si、wu、liou、qi、ba、jiou) acoustic models.
- Use mxup.scp to modify macro.init to generate macro.0
We copy output\macro.init to output\hmm\macro.0 first, and then use HHEd.exe to modify macro.0, with the following MATLAB commands:fid=fopen('output\mxup.scp', 'w'); fprintf(fid, 'MU 3 {*.state[2-4].mix}'); fclose(fid); copyfile('output/macro.init', 'output/hmm/macro.0'); cmd='HHEd -H output\hmm\macro.0 output\mxup.scp output\digitSyl.mnl'; dos(cmd);The corresponding batch commands are:copy /y output\macro.init output\hmm\macro.0 (@echo MU 3 {*.state[2-4].mix}) > output\mxup.scp HHEd -H output\hmm\macro.0 output\mxup.scp output\digitSyl.mnlThe contents of mxup.scp are shown next:Its function is to increase the number of mixture components (of states 2 ~ 4) from 1 to 3. The contents of the generated macro.0 are:
From the above contents, we can observe that the variances of the three mixtures of a given state are the same. But their mean vectors are different in order to better cover the dataset.
- Perform re-estimation to generate macro.1~macro.5
Now we can start training to find the best parameters for each acoustic model, with the MATLAB commands:emCount=5; for i=1:emCount sourceMacro=['output\hmm\macro.', int2str(i-1)]; targetMacro=['output\hmm\macro.', int2str(i)]; fprintf('%d/%d: 產生 %s...\n', i, emCount, targetMacro); copyfile(sourceMacro, targetMacro); cmd=sprintf('HERest -H %s -I output\\digitSylPhone.mlf -S output\\trainFea.scp output\\digitSyl.mnl', targetMacro); dos(cmd); endThe corresponding batch commands are:set current=0 :loop set /a prev=current set /a current+=1 copy /y output\hmm\macro.%prev% output\hmm\macro.%current% set cmd=HERest -H output\hmm\macro.%current% -I output\digitSylPhone.mlf -S output\trainFea.scp output\digitSyl.mnl echo %cmd% %cmd% if not %current%==5 goto :loop
In the above commands, we use macro.0 as the initial guess for corpus training to generate macro.1, and then use macro.1 to perform re-estimation to generate macro.2. This re-estimation is repeated five times to generate macro.1 ~ macro.5 in "output\hmm\macro.*".
- Generate file lists in trainFea.scp and testFea.scp
- Performance evaluation based on recognition rate
- Use digit.grammar to generate digit.net
After corpus training, we need to evaluate the recognition rate based on a test data set. First of all, we need to construct the lexicon net, as follows:Hparse digit.grammar output\digit.net
The contents of grammer.txt are:The contents of the generated digit.net are:
The schematic diagram of the net is shown next:
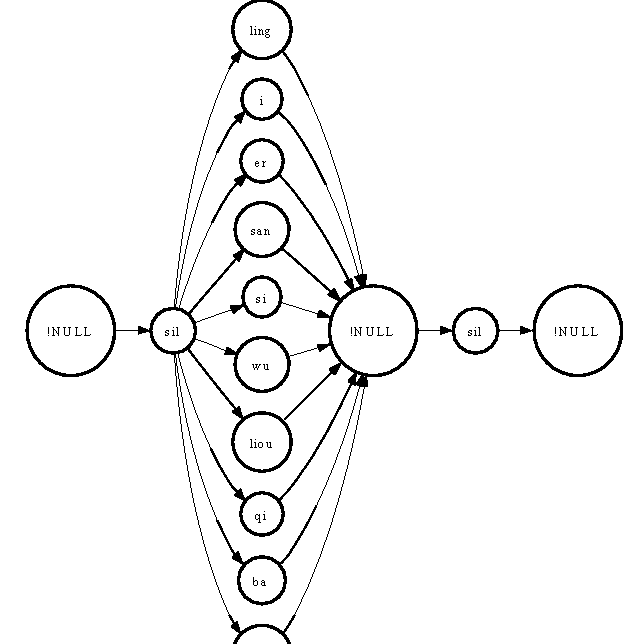
- Evaluate the recognition rates for both the training and test sets
This is achieved by the following HTK commands:HVite -H output\macro -l * -i output\result_test.mlf -w output\digit.net -S output\testFea.scp digitSyl.pam output\digitSyl.mnl
The contents of the output file result_test.mlf are:By using a similar command, we can also generate the recognition rate of the training set.
- Generate the confusion matrices for both inside and outside tests
Finally, we can use the following commands to generate the confusion matrices:findstr /v "sil" output\result_test.mlf > output\result_test_no_sil.mlf findstr /v "sil" digitSyl.mlf > output\answer.mlf HResults -p -I output\answer.mlf digitSyl.pam output\result_test_no_sil.mlf > output\outsideTest.txt type output\outsideTest.txt
The confusion matrix for the outside test is:Similarly, the confusion matrix for the inside test is:
As usually, the outside test is not as good as the inside test. One possible reason is that the training corpus is not big enough to cover a variety of accents from different individuals. Other possibilities could be the structures of the acoustic models. In the subsequent sections, we shall explore other model structures to improve the performance.
- Use digit.grammar to generate digit.net
Audio Signal Processing and Recognition (音訊處理與辨識)
