由於個人電腦的普及和運算速度的提高,「電腦輔助語言學習」(CALL, Computer Assisted Language Learning)的研發已經到達可以商業化的階段,其中又以「電腦輔助發音訓練」(CAPT, Computer Assisted Pronunciation Training)最受到矚目,因為其實用性很高,互動性很強,可以大量彌補口說語言師資的不足。一般而言,我們又把「電腦輔助發音訓練」簡稱為「語音評分」或「發音評分」等。
以口說英文為例,語音評分的目的是要以電腦來自動評斷一個人的一句英文發音是否標準,並和老外講的同一句話來進行比較,以圖表列出相近及相異之處,並以聲音或動畫來提示正確發音,讓使用者反覆練習,以改進個人的英語發音。語音評分的流程可以說明如下:
- 對標準語句及測試語句抽取出語音的特徵參數(通常是 MFCC, Mel-frequency Cepstral Coefficients)。
- 以 Viterbi Decoding 來進行 Forced Alignment,以便切出來每一個子音及母音。此部分需用到語者無關(Speaker-independent)的英文語音辨識核心。
- 對每一個子音及母音進行評分因素的擷取,包含音量、音高、音長等,以及之前已經取得的 MFCC。
- 對每一個評分因素進行個別評分,然後進行加權平均,以得到最後的評分結果。這些評分的因素有:
- 音色:語音的內容及發音的準確性,此部份的分數通常是經由計算 Acoustic Models 的機率值,並和類似音進行排名而得的分數,而不是直接和標準發音進行比較所得的分數。這是因為標準發音的範例可能有限(例如只有男生或女生),因此直接進行音色的相似度比對可能會造成使用者期望的誤差。
- 音調:經由每一個音節的音高曲線來和目標發音進行相似度比對。若是中文,就要加上聲調辨識,以便決定使用者的發音是否符合華語的聲調和變調規則。
- 韻律(或是音長):經由每一個音節的發音長度,來和目標語句進行相似度比對。
- 強度:經由每一個音節的發音音量,來和目標語句進行相似度比對。
這邊有一個簡單的範例,我們先使用老外講的標準語句:She had your dark suit in greasy wash water all year,經由 Forced Alignment 處理後,可以得到下列結果:
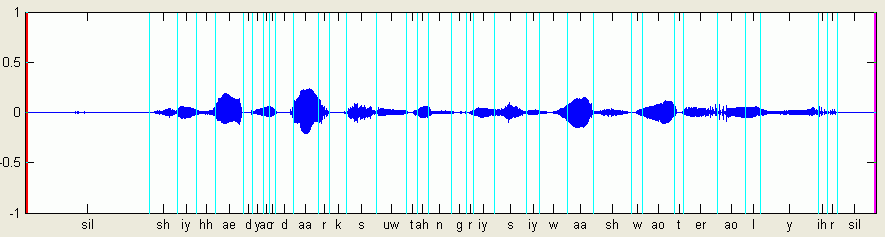 由上圖可看出,經由 Forced Alignment 之後,電腦已經將每一個音標所在的區域自動標示出來,一旦這些標示是對的,以後的步驟就很簡單,我們就可以針對每一個音標來進行個別評分,然後再計算總分。因此這部分「切音」的結果可說是影響評分系統的最重要因素。(為了使切音的結果正確,我們的英文辨識引擎使用了兩個語料,一個是傳統的英文語料 TIMIT,另一個是台灣地區的英文語料,此部分的語料收集是由工研院負責統籌,參與錄音與整理語料的學校包含台灣大學、清華大學、交通大學、成功大學、師範大學)。
由上圖可看出,經由 Forced Alignment 之後,電腦已經將每一個音標所在的區域自動標示出來,一旦這些標示是對的,以後的步驟就很簡單,我們就可以針對每一個音標來進行個別評分,然後再計算總分。因此這部分「切音」的結果可說是影響評分系統的最重要因素。(為了使切音的結果正確,我們的英文辨識引擎使用了兩個語料,一個是傳統的英文語料 TIMIT,另一個是台灣地區的英文語料,此部分的語料收集是由工研院負責統籌,參與錄音與整理語料的學校包含台灣大學、清華大學、交通大學、成功大學、師範大學)。
使用我講的好的測試語句,下圖是波形及經由 Forced Alignment 的結果,基本上的切音位置都是正確的:
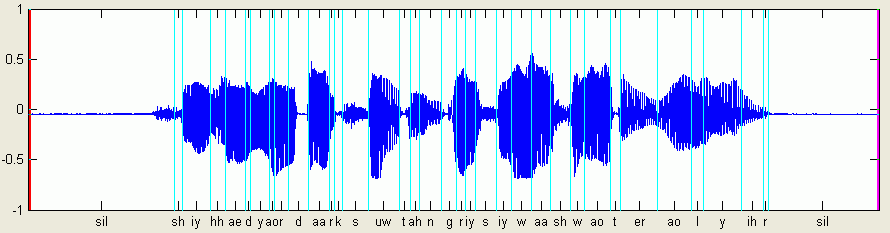 得到的評分結果是:
Pitch (22.40%): 93.64
Magnitude (7.45%): 79.68
Rhythm (17.24%): 85.25
Pronunciation (52.91%): 76.29
---------------------------------------------
Score: 83.10
若使用我講的差的測試語句,下圖是波形及經由 Forced Alignment 的結果:
得到的評分結果是:
Pitch (22.40%): 93.64
Magnitude (7.45%): 79.68
Rhythm (17.24%): 85.25
Pronunciation (52.91%): 76.29
---------------------------------------------
Score: 83.10
若使用我講的差的測試語句,下圖是波形及經由 Forced Alignment 的結果:
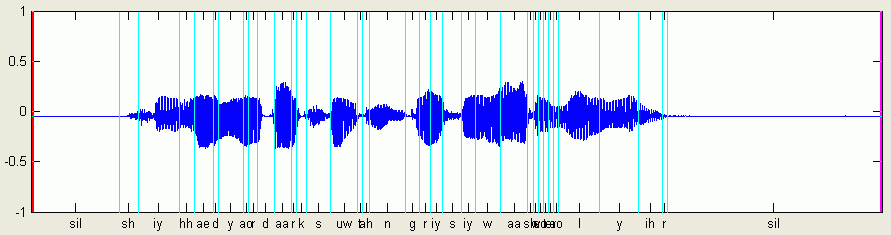 得到的評分結果是:
Pitch (22.40%): 91.58
Magnitude (7.45%): 85.48
Rhythm (17.24%): 80.31
Pronunciation (52.91%): 72.77
---------------------------------------------
Score: 80.98
在這一句英文中,我故意漏掉「wash」這個英文字,因此會導致在進行切音的位置錯誤,由上圖可以看出,wash 的前半部被放在 water 語音的位置,而 water 則整個被壓縮了。由於唸法的不完整,造成切字的錯誤,因此整段話的分數就會比較低。
得到的評分結果是:
Pitch (22.40%): 91.58
Magnitude (7.45%): 85.48
Rhythm (17.24%): 80.31
Pronunciation (52.91%): 72.77
---------------------------------------------
Score: 80.98
在這一句英文中,我故意漏掉「wash」這個英文字,因此會導致在進行切音的位置錯誤,由上圖可以看出,wash 的前半部被放在 water 語音的位置,而 water 則整個被壓縮了。由於唸法的不完整,造成切字的錯誤,因此整段話的分數就會比較低。
相關應用方面,可以列出如下:
- 語言學習軟體:由於一般個人電腦的運算能力已經很強大,因此我們可以在一般個人電腦上進行完整的語音評分,可以用在各種語言學習軟體,以達到更客觀的評分與分析,以進行電腦輔助口說英語教學。
- 英文覆讀機、電子英文學習機、PDA:由於語音評分需要的計算量相當大,因此比較難在於低階的嵌入式系統(例如 8 位元或是 16 位元的 MCU)。但如果將平台放寬到 32 位元的平台(例如 ARM),我們就可以進行比較完整的語音評分,可以隨時隨地進行電腦輔助口說英語教學。(在低階的平台上,還是可以進行音調評分。)
Audio Signal Processing and Recognition (音訊處理與辨識)
