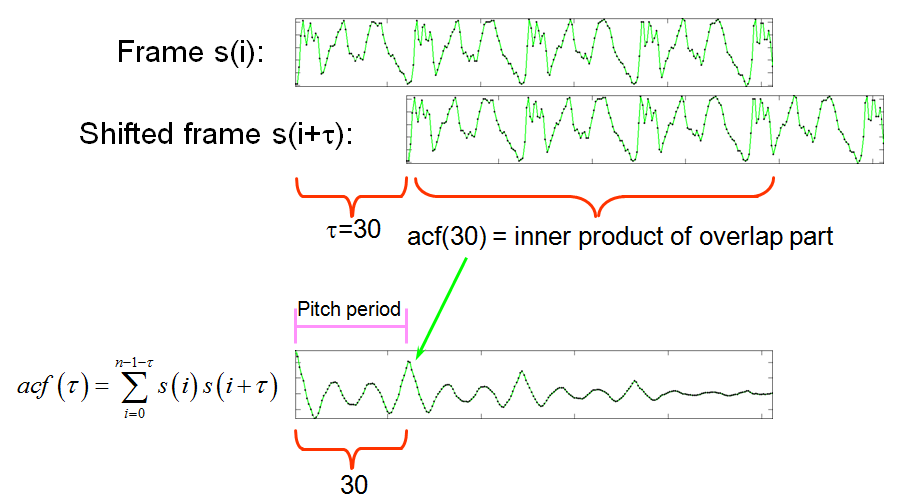
In this section, we shall introduce the auto-correlation function (ACF) for pitch tracking. This is a time-domain method which estimates the similarity between a frame $s(i), i = 0, \dots, n-1$, and its delayed version via the auto-correlation function:
$$acf(\tau)=\sum_{i=0}^{n-1-\tau}s(i)s(i+\tau)$$
where $\tau$ is the time lag in terms of sample points. The value of $\tau$ that maximizes $acf(\tau)$ over a specified range is selected as the pitch period in sample points. The following figure demonstrates the operation of ACF:
In other words, we shift the delayed version n times and compute the inner product of the overlapped parts to obtain n values of ACF.
Take my utterance sunday.wav for example. If we take a frame of 512 points starting from the 9000th point, which corresponds to the vowel part of "day", the ACF result is the following example:
The maximum of ACF occurs at the first point, which is obviously not what we want. If we set the values around the first maximum to be $-\infty$, we can identify the second maximum located at index 131 and the corresponding pitch is fs/(131-1) = 16000/130 = 123.08 Hz, or 46.94 semitones.
The point of ACF at index 131 is referred as the pitch point for ACF. In order to identify the pitch point of ACF automatically, we can simply set the first few points of ACF to be $-\infty$ and then find the maximal point of ACF. Please refer to the following example.
In the above figure, the first plot if the frame, the second plot is the original ACF and the modified ACF. The red circle is the maximal point of the modified ACF, which is also the correct pitch point.
The modified ACF is obtained by setting ACF to $-\infty$ at some regions. More specifically, suppose human's pitch is within the range of [40, 1000] (Hz), then we have the following inequality:
$$ 40 \leq \frac{fs}{pp-1} \leq 1000$$
This leads to the range of $pp$ (pitch point):
$$ \frac{fs}{1000}+1 \leq pp \leq \frac{fs}{40}+1$$
By using the range of $pp$, we can perform pitch tracking on a stream of audio signals, as shown in the next example.
In the above example, we use simple volume thresholding with a threshold equal to one eighth of the maximum volume. That is, if a frame has a volume less than 1/8 of the maximum volume, then its pitch is set to zero. From the last plot of the above figure, it is obvious that the values of the pitch curve is mostly correct except for several erroneous points which deviate from the presumably smooth pitch curve. This discontinuous points will cause squeaky sounds during the playback of the pitch curve. We usually apply a smoothing operator (such as median filters) on the pitch curve as a post-process to eliminate erroneous points. Without using the smoothing operator, the results are shown in the following links:
Since the above script is useful for pitch tracking, we have packed it into a function "pitchTrackBasic.m", with an example shown next:
There are several variations of ACF that are also used commonly:
The previously defined ACF has a tapering effect since a larger $\tau$ will use a smaller overlap for the calculation. As an alternative, we can compute a new ACF by dividing the inner product by the size of the overlapped region, as shown in the next equation:
$$acf(\tau)=\sum_{i=0}^{n-1-\tau}\frac{s(i)s(i+\tau)}{n-\tau}$$
Due to the smaller overlap, the last few points of ACF may be unstable, as shown in the following example.
The unstable ACF is reflected in the corresponding pitch tracking:
Another method to avoid tapering-off is to shift only the first half of a frame, as shown in the next equation:
$$acf(\tau)=\sum_{i=0}^{n/2}s(i)s(i+\tau)$$
The overlap region will always be half of the frame size and the obtain ACF will not taper off. Please refer to the following example.
However, the resultant ACF has a length of half of the frame size. Now you run into the risk of not being able to detect low pitch less than 16000/256 = 62.5 Hz. To avoid this, you might want to double the frame size (at the cost of reducing time resolution), as shown next: