Slides for this chapter
From the previous chapter, you should already know how to find the pitch by visual inspection and some simple computation. If we want the computer to automatically identify the pitch from a stream of audio signals, then we need to have some reliable methods for such a task of "pitch tracking". Once the pitch vector is identified, it can be used for various applications in audio signal processing, including:
- Melody Recognition: To retrieve a song from a music database based on a the user's singing or humming input. This is also known as QBSH (Query by Singing/Humming).
- Tone Recognition for tonal language (such as Mandarin): To identify each syllable's tone in an utterance by the user. This is usually used in computer assisted pronunciation training (CAPT).
- Prosody Analysis for TTS (text-to-speech): To analyze and predict the best F0 curve for TTS applications.
- Intonation Assessment: To compute the similarity between a test and a target utterances for CAPT.
- Speech recognition: To use pitch as an extra cue to improve the recognition rates of speech recognition.
In summary, pitch tracking is a fundamental step toward other important tasks for audio signal processing. Related research on pitch tracking has been going on for decades, and it still remains an hot topic in the literature. Therefore we need to know the basic concept of pitch tracking as a stepstone for other advanced audio processing techniques.
Pitch tracking follows the general processing of short-term analysis for audio signals, as follows.
- Chop the audio signals into frames of 20 ms or so. Overlap is allowed between neighboring frames.
- Compute the pitch of each frame.
- Eliminate pitch from silence or unvoiced sounds. This can be done by using volume thresholding or pitch range thresholding.
- Smooth the pitch curve using median filters or other similar methods.
In the processing frame blocking, we allow overlap between neighboring frames to reduce discontinuity between them. We can define "frame rate" as the frames per second for our analysis. For instance, if fs = 11025 Hz, frame size = 256, overlap = 84, then the frame rate is equal to fs/(frameSize-overlap) = 11025/(256-84) = 64. In other words, if we wish to have real-time pitch tracking (for instance, on the platform of micro-controllers), then the computer should be able to handle 64 frames per second. A small overlap will lead to a low frame rate. The process of frame blocking is shown next.
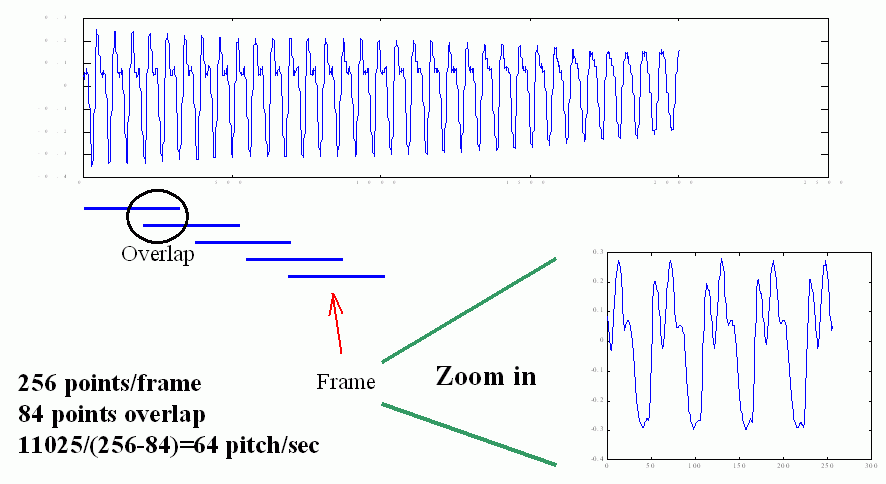
When we choose the frame size and the overlap, we need to consider the following factors.
- The frame size should cover at least two fundamental periods to fully capture the characteristics of the audio signals. Suppose that the pitch range of human voices is between 50 to 1000 Hz, and the sample rate is 16000 Hz, then we can derive the range of the frame size, as follows.
- If f = 50 Hz, then the fundamental period = fs/f = 16000/50 = 320 points and the frame size should be 2*320 = 640 points.
- If f = 1000 Hz, then the fundamental period = fs/f = 16000/1000 = 16 points and the frame size should be at least 2*16 = 32 points.
- The frame size should not too big, otherwise it cannot capture time-varying characteristics of audio signals. A big frame size also require more computing time to process the frame.
- The overlap is determined by the computing power of your platform. A big overlap leads to a big frame rate and thus requries more computing power. If we do not have enough computing power, we can reduce the overlap or even make the overlap negative.
There are a number of methods to derive a pitch value from a single frame. Generally, these methods can be classified into time-domain and frequency-domain methods, as follows.
- Time-domain methods
- ACF: Autocorrelation function
- AMDF: Average magnitude difference function
- SIFT: Simple inverse filter tracking
- Frequency-domain methods
- Harmonic product spectrum method
- Cepstrum method
These methods will be covered in the rest of this chapter.
Audio Signal Processing and Recognition (音訊處理與辨識)
