The procedure from human voice production to voice recognition involves the following steps:
- Rapid open and close of your vocal cords (or glottis) to generate the vibration in air flow.
- Resonance of the pharyngeal cavity, nasal cavity, and oral cavity.
- The vibration of air.
- The vibration of the ear drum (or tympanum).
- The reception of the inner ear.
- The recognition by the brain.
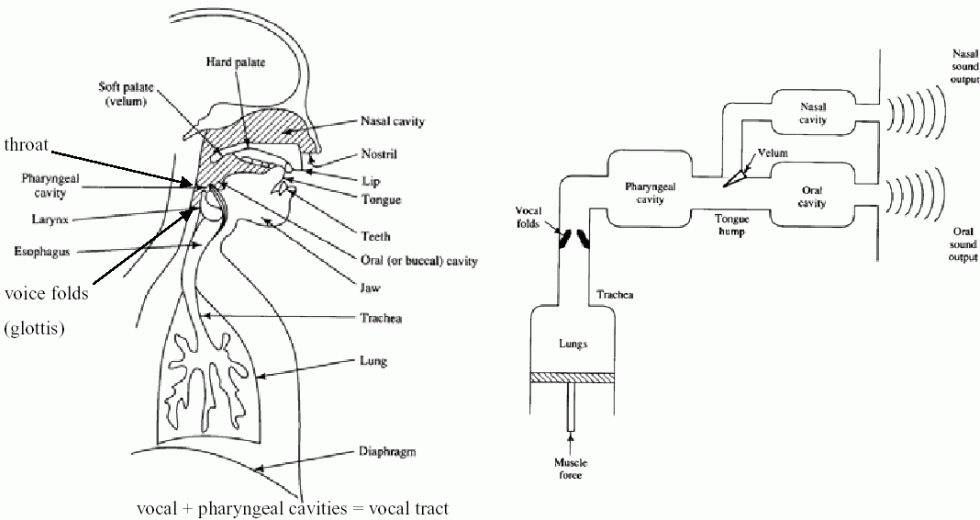
The production mechanism of human voices.
人聲的發音機制
- The vibration frequency of the vocal cords determines the pitch of the voices.
- The positions/shapes of your lips, tongue, and nose determine the timbre.
- The compression from your lungs determine the loudness of the voices.
The following figure demonstrates the airflow velocity around the glottis and the voice signals measured around the mouth.
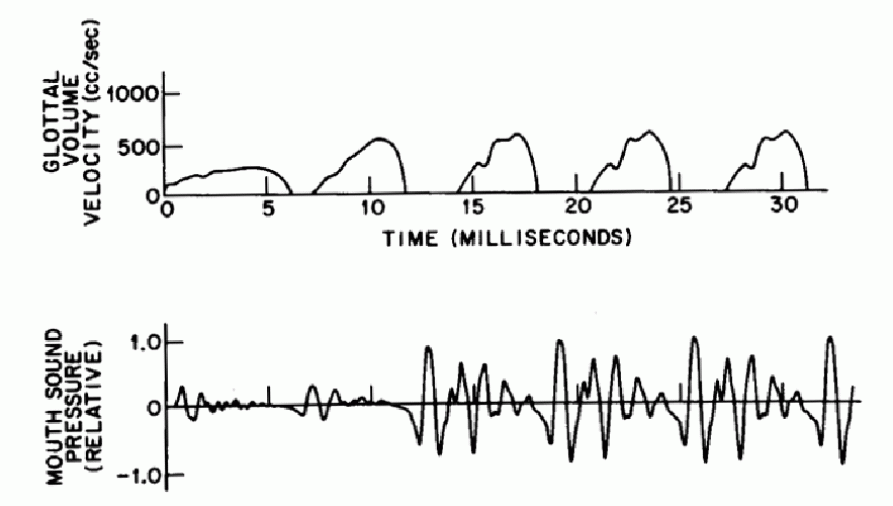
Airflow velocity around the glottis and the resultant voices signals
You can observe the movement of the vocal cords from the following link:
In fact, it is not easy to capture the movements of vocal cords due to its high frequency in movement. So we need to have high-speed cameras for such purpose, for instance:
We can conceive the production of human voices as a source-filter model where the source is the airflow caused by the vocal cords, and the filter includes the pharyngeal/nasal/oral cavities. The following figure shows the representative spectrum for each stage:
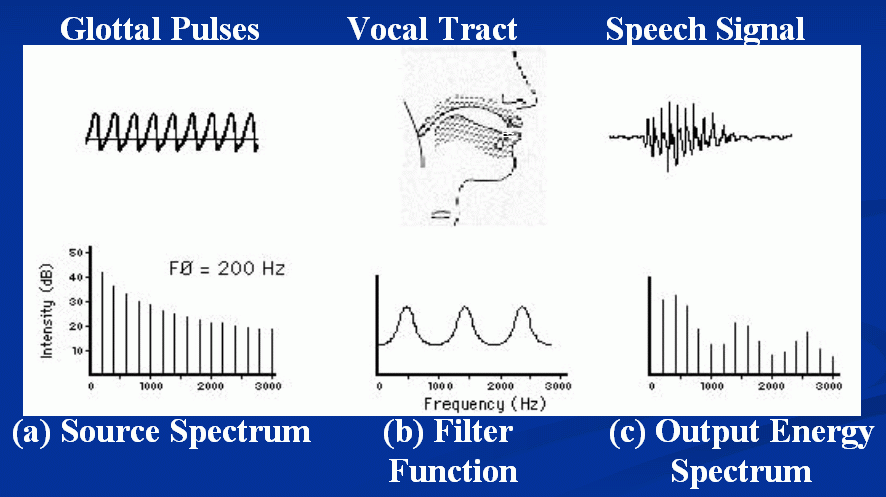
Source-filter model and the corresponding spectra
人聲發音過程與與頻譜的對應
We can also use the following block diagram to represent the source-filter model of human voice production:
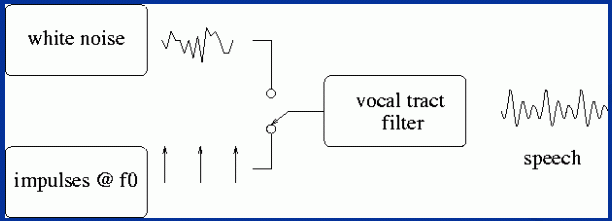
Block diagram representation of source-filter model
人聲發音過程的數學模型
In general, a regular vibration of the glottis will generate quasi-periodic voiced sounds. On the other hand, if the source is irregular airflow, then we will have unvoiced sounds. Take the utterance of "six" for example:
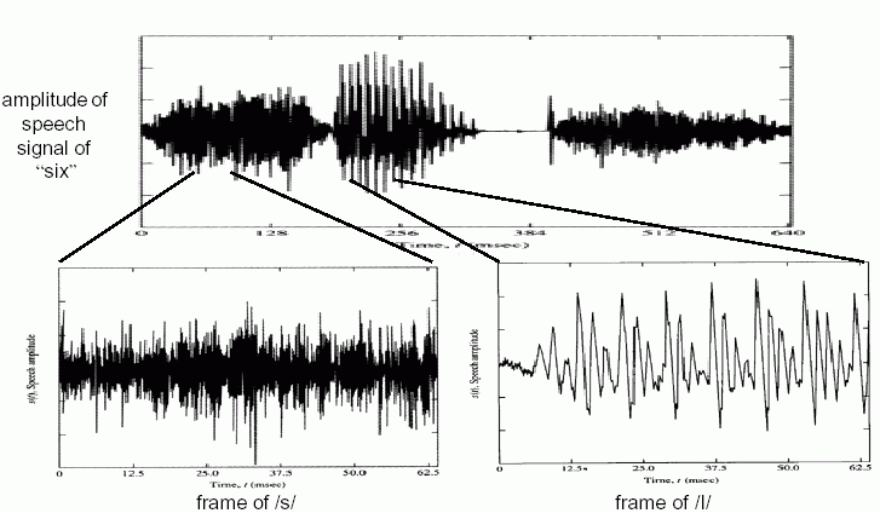
Unvoiced and voiced sounds
氣音和有聲音
We can clearly observe that "s" and "k" are unvoiced sounds, while "i" is a voiced sound.
For Mandarin, almsot all unvoiced sounds happen at the beginning of a syllable. Take the utterance of "清" as in "清華大學" for example:
- No vibration from the glottis. Close your teech and push forward your tongue tip against the lower teeth to generate the unvoiced sound "ㄑ" by a jet of airflow.
- Keep almost the sampe position but start glottis vibration to pronunce the voiced "ㄧ".
- Keep glottis vibrate but retract your tongue to pronuced the final voiced "ㄥ".
Here are some terminologies in both English and Chinese for your reference:
- Cochlea:耳蝸
- Phoneme:音素、音位
- Phonics:聲學;聲音基礎教學法(以聲音為基礎進而教拼字的教學法)
- Phonetics:語音學
- Phonology:音系學、語音體系
- Prosody:韻律學;作詩法
- Syllable:音節
- Tone:音調
- Alveolar:齒槽音
- Silence:靜音
- Noise:雜訊
- Glottis:聲門
- larynx:喉頭
- Pharynx:咽頭
- Pharyngeal:咽部的,喉音的
- Velum:軟顎
- Vocal chords:聲帶
- Glottis: 聲門
- Esophagus:食管
- Diaphragm:橫隔膜
- Trachea:氣管
Audio Signal Processing and Recognition (音訊處理與辨識)
