We shall introduce several time-domain methods for EPD in this section.
首先我們來介紹如何在時域進行音高追蹤。
The first method uses volume as the only acoustic feature for EPD. This is the most intuitive method with least computation. We only need to determine a volume threshold. Any frame with a volume less than the threshold is regarded as silence. However, how to determine a good volume threshold is not obvious. As a result, the best strategy is to use a set of labeled training data to find the best value for achieving the minimum error.
第一種方法,是直接使用音量來進行端點偵測的方法。這是一種最簡單的方法,只要音量小於某個門檻值,我們就認定是靜音或是雜訊,至於這個門檻值如何決定,除了靠人的直覺外,比較客觀的方法,還是靠大量的測試資料來決定最佳值。
In the following example, we shall use four different ways to compute volume thresholds for EPD of the wave file sunday.wav:
下列這個範例使用音量來對 sunday.wav 進行端點偵測。在此範例中,我們使用 4 種不同方法來計算音量門檻植,並將結果畫出來以便觀察,如下:
In the above example, we have used four methods to compute the volume thresholds. These four methods all have their weakness, as explained next:
在上述的範例中,我們使用了三個音量門檻值來進行端點偵測:
- A ratio times the maximal volume: Not reliable if there is an impulse in volume due to plosive sounds.
- A ratio times the median of the volume: Not reliable when silence occupies more than half of the audio signals.
- The minimal volume times a constant: This could go wrong if the noise if too big. Moreover, it is likely for some recordings to have a frame of zero volume.
- The volume of the first frame times a constant: This could go wrong if the first frame of the recording is unstable, which is not rare in practice.
- 音量最大值的 0.1:此方法在音量忽大忽小時或雜訊太強時,會發生錯誤。
- 音量最小值的 5 倍:此方法在雜訊太強時,會發生錯誤。
- 第一個音框的音量的 4 倍:此方法假設一開始是靜音,但若一開始就有聲音,或是錄音器材一開始有偏移,此做法就很容易發生錯誤。
In the above example, the volume threshold is determined as
The ratios or constants in the above four methods should be determined through labeled training data. It should be noted that wave files of different characteristics (recordings via uni-directional or omni-directional microphones, different sample rates, different bit resolutions, different frame sizes and overlaps) will have a different best thresholds.
當然,上述方法中的相關參數值(0.1、5、4 等值),都只能適用於這個音訊檔案,若要找出對其他聲音也完全適用的參數值,就要靠大量資料的測試才能得到。
Of course, you also create a new threshold by using linear combinations of these thresholds, etc.
當然,你也可以靠你的創意和智慧,別出心裁,想一個決定音量門檻植的最佳方法,例如採用音量最大值和最小值的加權平均等等。
From the above example, it is obvious that the leading unvoiced sound is likely to be misclassified as silence. Moreover, a single threshold might not perform well if the volume varies a lot. As a result, an improved method can be stated next:
若是聲音很乾淨,雜訊不大,那麼使用音量來偵測端點可得到不錯的效果。但是如果碰到下列問題,這個簡單的方法就行不通:
- 雜訊比較強
- 氣音比較多
- 同一句話的音量變化太大
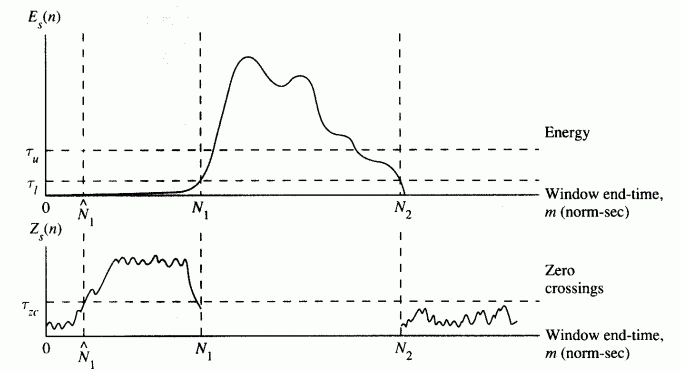
- Use a upper threshold tu to determine the inital end-points.
- Extend the boundaries until they reach the lower threshold tl.
- Extend the boundaries further until they reach the ZCR threshold tzc.
- 以高音量門檻值(tu)為標準,決定端點。
- 將端點前後延伸到低音量門檻值(tl)處。
- 再將端點前後延伸到過零率門檻(tzc)處,以包含語音中的氣音部分。
If we apply the above method for EPD of sunday.wav, the result can plotted as follows: 我們有一個端點偵測的函數,若對 sunday.wav 進行處理,得到的結果如下:
In the above plot, the red and green lines indicate the beginning and end of sound, respectively. This example uses the function epdByVolZcr.m in the SAP Toolbox, which use volume and ZCR as mentioned above for EPD. 其中紅線表示聲音的開始,綠線表示聲音的結束。這個範例用到了 SAP Toolbox 裡面的 endPointDetect.m 函數,此函數即是使用音量和過零率來決定端點。
Now it should be obvious that the most difficult part in EPD is to distinguish unvoiced sounds from silence reliably. One way to achieve this goal is to use high-order difference of the waveform as a time-domain features. For instance, in the following example, we use order-1, 2, 3 differences on the waveform of beautifulSundays.wav:
It is obvious that the high-order difference (HOD) on the waveform can let us identify the unvoiced sound more easily for this case. Therefore you can take the union of high-volume and high HOD regions to have most robust of EPD.
事實上,我們也可以反覆使用波形的微分,再計算音量,就可以凸顯氣音的部分,例如:
From the above example, a possible simple way of combining volume and HOD for EPD can be stated as follows:
- Compute volume (VOL) and the absolute sum of order-n difference (HOD).
- Select a weighting factor w within [0, 1] to compute a new curve VH = w*VOL + (1-w)*HOD.
- Find a ratio r to compute the threshold t of VH to determine the end-points. The threshold is equal to VHmin+(VHmax-VHmin)*r.
The above method involves three parameters to be determined: n, w, r. Typical values of these parameters are n = 1, w = 0.76, and r = 0.012. However, these values vary with data sets. It is always advisable to have these values tuned by using the target data set for a more robust result.
在上圖中,隨著我們對 frameMat 的一再微分,氣音的音量就會越來越明顯,因此可用來偵測氣音的存在。
A more comprehensive version of EPD using volume and HOD is epdByVolHod.m in the SAP toolbox. Please see the following example.
在 SAP 工具箱內的 epdByVolHod.m 即是使用音量和 HOD 來進行端點偵測,請見下列使用範例。
In general, the joint use of volume and HOD can perform decent EPD for most recordings, except for those with high environmental noise.
一般而言,同時使用音量及 HOD,可以對一般錄音進行不錯的端點偵測,但是此方法也有弱點,但環境雜訊太大時,此方法的正確率一樣會降低。
Of course, there are still plenty of other methods for EPD on time domain. It is up to you to create ingenious methods for EPD.
當然,還有很多時域的方法,就看你的巧思了!
Audio Signal Processing and Recognition (音訊處理與辨識)
