We shall introduce several time-domain methods for EPD in this section.
The first method uses volume as the only acoustic feature for EPD. This is the most intuitive method with least computation. We only need to determine a volume threshold. Any frame with a volume less than the threshold is regarded as silence. However, how to determine a good volume threshold is not obvious. As a result, the best strategy is to use a set of labeled training data to find the best value for achieving the minimum error.
In the following example, we shall use four different ways to compute volume thresholds for EPD of the wave file sunday.wav:
In the above example, we have used four methods to compute the volume thresholds. These four methods all have their weakness, as explained next:
A ratio times the maximal volume: Not reliable if there is an impulse in volume due to plosive sounds.
A ratio times the median of the volume: Not reliable when silence occupies more than half of the audio signals.
The minimal volume times a constant: This could go wrong if the noise if too big. Moreover, it is likely for some recordings to have a frame of zero volume.
The volume of the first frame times a constant: This could go wrong if the first frame of the recording is unstable, which is not rare in practice.
Since there is no simply way to choose a volume threshold for EPD of all kinds of recordings, all we can expect is look into more sophisticated methods for determining the threshold. A more robust example of EPD is shown next.
In the above example, the volume threshold is determined as
volTh=(volMax-volMin)*epdPrm.volRatio+volMin;
where epdPrm.volRatio is 0.1, and volMin and volMax are 3% and 97% percentiles of the volumes in an utterance, respectively.
The ratios or constants in the above four methods should be determined through labeled training data. It should be noted that wave files of different characteristics (recordings via uni-directional or omni-directional microphones, different sample rates, different bit resolutions, different frame sizes and overlaps) will have a different best thresholds.
Of course, you also create a new threshold by using linear combinations of these thresholds, etc.
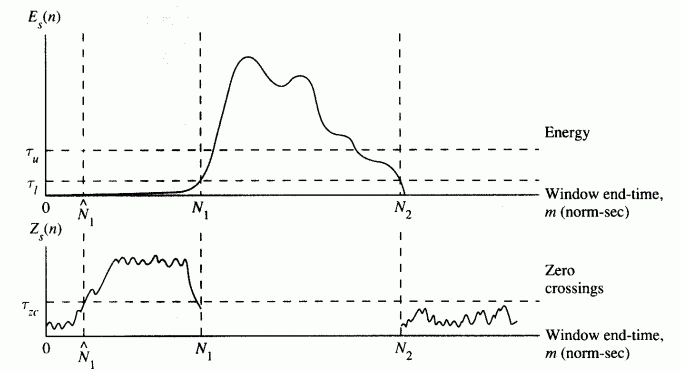
From the above example, it is obvious that the leading unvoiced sound is likely to be misclassified as silence. Moreover, a single threshold might not perform well if the volume varies a lot. As a result, an improved method can be stated next:
Use a upper threshold tu to determine the inital end-points.
Extend the boundaries until they reach the lower threshold tl.
Extend the boundaries further until they reach the ZCR threshold tzc.
This method is illustrated as follows.
The above improved method uses only three thresholds, hence it is possible to use grid search to find the best values via a set of labeled training data.
If we apply the above method for EPD of sunday.wav, the result can plotted as follows:
In the above plot, the red and green lines indicate the beginning and end of sound, respectively. This example uses the function epdByVolZcr.m in the SAP Toolbox, which use volume and ZCR as mentioned above for EPD.
Now it should be obvious that the most difficult part in EPD is to distinguish unvoiced sounds from silence reliably. One way to achieve this goal is to use high-order difference of the waveform as a time-domain features. For instance, in the following example, we use order-1, 2, 3 differences on the waveform of beautifulSundays.wav:
It is obvious that the high-order difference (HOD) on the waveform can let us identify the unvoiced sound more easily for this case. Therefore you can take the union of high-volume and high HOD regions to have most robust of EPD.
From the above example, a possible simple way of combining volume and HOD for EPD can be stated as follows:
Compute volume (VOL) and the absolute sum of order-n difference (HOD).
Select a weighting factor w within [0, 1] to compute a new curve VH = w*VOL + (1-w)*HOD.
Find a ratio r to compute the threshold t of VH to determine the end-points. The threshold is equal to VHmin+(VHmax-VHmin)*r.
The above method involves three parameters to be determined: n, w, r. Typical values of these parameters are n = 1, w = 0.76, and r = 0.012. However, these values vary with data sets. It is always advisable to have these values tuned by using the target data set for a more robust result.
A more comprehensive version of EPD using volume and HOD is epdByVolHod.m in the SAP toolbox. Please see the following example.
In general, the joint use of volume and HOD can perform decent EPD for most recordings, except for those with high environmental noise.
Of course, there are still plenty of other methods for EPD on time domain. It is up to you to create ingenious methods for EPD.