When we analyze audio signals, we usually adopt the method of short-term analysis since most audio signals are more or less stable within a short period of time, say 20 ms or so. When we do frame blocking, there may be some soverlap between neighboring frames to capture subtle change in the audio signals. Note that each frame is the basic unit for our analysis. Within each frame, we can observe the three most distinct acoustic features, as follows.
- Volume: This feature represents the loudness of the audio signal, which is correlated to the amplitude of the signals. Sometimes it is also referred to as energy or intensity of audio signals.
- Pitch: This feature represents the vibration rate of audio signals, which can be represented by the fundamental frequency, or equivalently, the reciprocal of the fundamental period of voiced audio signals.
- Timbre: This feature represents the meaningful content (such as a vowel in English) of audio signals, which is characterized by the waveform within a fundamental period of voice signals.
當我們在分析聲音時,通常以「短時距分析」(Short-term Analysis)為主,因為音訊在短時間內是相對穩定的。我們通常將聲音先切成音框(Frame),每個音框長度大約在 20 ms 左右,再根據音框內的訊號來進行分析。在一個特定音框內,我們可以觀察到的三個主要聲音特徵可說明如下:
- 音量(Volume):代表聲音的大小,可由聲音訊號的震幅來類比,震幅越大,代表此聲音波形的音量越大。音量又稱為能量(Energy)或強度(Intensity)等。
- 音高(Pitch):代表聲音的高低,可由基本頻率(Fundamental Frequency)來類比,這是基本週期(Fundamental Period)的倒數。聲音的基本頻率越高,代表音高越高;反之,聲音的基本頻率越低,代表音高越低。
- 音色(Timbre):代表聲音的內容(例如英文的母音),可由每一個波形在一個基本週期的變化來類比。不同的音色即代表不同的音訊內容,例如不同的字母有不同的發音,都是由於音色不同而產生。
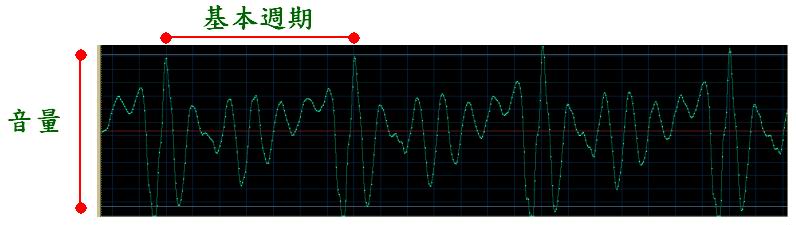
Take human voices as an example, then the above three acoustic features will correlates to some physical quantities:
如果是用人聲來說明,這些語音特徵的物理意義如下:
- Volume: It correlates to the compression of your lungs. A large volume of audio signals corresponds to a large compression.
- Pitch: It correlates to the vibration frequency of your vocal cord. A high pitch corresponds to a high vibration frequency.
- Timbre: It correlates to the positions and shapes of your lips and tongue. Different timbres corresponds to different positions and shapes of your lips and tongue.
- 音量:代表肺部壓縮力量的大小,力量越大,音量越大。
- 音高:代表聲帶震動的快慢,震動越快,音高會越高。
- 音色:代表嘴唇和舌頭的位置和形狀,不同的位置和形狀,就會產生不同的語音內容。
We shall explain methods to extract these acoustic features in the other chapters of this book. It should be noted that these acoustic features mostly corresponds to human's "perception" and therefore cannot be represented exactly by mathematical formula or quantities. However, we still try to "quantitify" these features for further computer-based analysis in the hope that the used formula or quantities can emulate human's perception as closely as possible.
有關這些語音特徵的抓取和分析,會在後續章節有詳細說明。特別要注意的是,這些特徵都是代表「人耳的感覺」,並沒有一定的數學公式可尋,所以當我們試著在「量化」這些特徵時,只是根據一些數據和經驗來量化,來盡量逼近人耳的感覺,但並不代表這些「量化」後的數據或公式就可以完全代表聲音的特徵。
The basic approach to the extraction of audio acoustic features can be summarized as follows:
- Perform frame blocking such that a strem of audio signals is converted to a set of frames. The time duration of each frame is about 20~30 ms. If the frame duration is too big, we cannot catch the time-varying characteristics of the audio signals. On the other hand, if the frame duration is too small, then we cannot extract valid acoustic features. In general, a frame should be contains several fundamental periods of the given audio signals. Usually the frame size (in terms of sample points) is equal to the powers of 2 (such as 256, 512, 1024 ,etc) such that it is suitable for fast fourier transform.
- If we want to reduce the difference between neighboring frames, we can allow overlap between them. Usually the overlap is 1/2 to 2/3 of the original frame. The more overlap, the more computation is needed.
- Assuming the audio signals within a frame is stationary, we can extract acoustic features such as zero crossing rates, volume, pitch, MFCC, LPC, etc.
- We can perform endpoint detection based on zero crossing rate and volume, and keep non-silence frames for further analysis.
音訊特徵抽取的基本方式如下:
- 將音訊切成一個個音框,音框長度大約是 20~30 ms。音框若太大,就無法抓出音訊隨時間變化的特性;反之,音框若太小,就無法抓出音訊的特性。一般而言,音框必須能夠包含數個音訊的基本週期。(另,音框長度通常是 2 的整數次方,若不是,則在進行「傅立葉轉換」時,需補零至 2 的整數次方,以便使用「快速傅立葉轉換」。)
- 若是希望相鄰音框之間的變化不是太大,可以允許音框之間有重疊,重疊部分可以是音框長度的 1/2 到 2/3 不等。(重疊部分越多,對應的計算量也就越大。)
- 假設在一個音框內的音訊是穩定的,對此音框求取特徵,如過零率、音量、音高、MFCC 參數、LPC 參數等。
- 根據過零率、音量及音高等,進行端點偵測(Endpoint Detection),並保留端點內的特徵資訊,以便進行分析或辨識。
When we are performing the above procedures, there are several terminologies that are used often:
- Frame size: The sampling points within each frame
- Frame overlap: The sampling points of the overlap between consecutive frames
- Frame step (or hop size): This is equal to the frame size minus the overlap.
- Frame rate: The number of frames per second, which is equal to the sample frequency divided by the frame step.
在進行上述分析時,有幾個名詞常用到,說明如下:
- 音框點數(Frame Size):每一個音框所含有的點數。
- 音框重疊量(Frame Overlap):音框之間重疊的點數。
- 音框跳距(Frame Step or Hop Size):此音框起點和下一個音框起點的距離點數,等於音框點數減去音框重疊。
- 音框率(Frame Rate):每秒出現的音框數目,等於取樣頻率除以音框跳距。
For instance, if we have a stream of audio signals with sample frequency fs=16000, and a frame duration of 25 ms, overlap of 15 ms, then
- Frame size = fs*25/1000 = 400 (sample points)。
- Frame overlap = fs*15/1000 = 240 (sample points)。
- Frame step (or hop size) = 400-240 = 160 (sample points)。
- Frame rate = fs/160 = 100 frames/sec。
舉例而言,如果取樣頻率 fs=16000 且每一個音框所對應的時間是 25 ms,重疊 15 ms,那麼
- Frame size = fs*25/1000 = 400 點。
- Frame overlap = fs*15/1000 = 240 點。
- Frame step (or hop size) = 400-240 = 160 點。
- Frame rate = fs/160 = 100 frames/sec。
Audio Signal Processing and Recognition (音訊處理與辨識)
