Tutorial on text-dependent speaker recognition
In this tutorial, we shall explain the basics of text-dependent speaker identification using MFCC as features and DTW as comparison method. The dataset is availabe upon request.
Contents
Preprocessing
Before we start, let's add necessary toolboxes to the search path of MATLAB:
addpath d:/users/jang/matlab/toolbox/utility addpath d:/users/jang/matlab/toolbox/sap addpath d:/users/jang/matlab/toolbox/machineLearning
Note that all the above toolboxes can be downloaded from the author's toolbox page.
For compatibility, here we list the platform and MATLAB version that we used to run this script:
fprintf('Platform: %s\n', computer); fprintf('MATLAB version: %s\n', version); scriptStartTime=tic;
Platform: PCWIN64 MATLAB version: 9.6.0.1214997 (R2019a) Update 6
Options for speaker identification
First of all, all the options for our speaker identification can be obtain as follows:
sidOpt=sidOptSet
sidOpt =
struct with fields:
method: 'dtw'
useGtEpd: 0
epdFcn: 'epdByVol'
auDir01: 'd:\dataSet\mir-2010-speakerId_label\session01'
auDir02: 'd:\dataSet\mir-2010-speakerId_label\session02'
outputDir: 'output/mir-2010-speakerId_label'
errorLogFile: 'output/mir-2010-speakerId_label/error.log'
maxSpeakerNum: Inf
sentenceNumPerSpeaker: Inf
mixData: 0
feaType: 'mfcc'
useEnergy: 1.00
temporalNormMode: 1.00
feaTransformMode: 0
transformedFeaDim: 10.00
useWaveformNormalization: 0
useIntFea: 0
dtwFunc: 'dtw2'
useDtwPartialComputation: 0
The contents of sidOpt can be shown next:
type sidOptSet.m
function sidOpt=sidOptSet
% sidOptSet: Set parameters for speaker identification/verification
% ====== Add necessary paths
addpath d:/users/jang/matlab/toolbox/utility
addpath d:/users/jang/matlab/toolbox/machineLearning
addpath d:/users/jang/matlab/toolbox/sap
addpath d:/users/jang/matlab/toolbox/asr -end
% ====== Method
sidOpt.method='dtw'; % 'dtw' (for text-dependent speaker ID) or 'gmm' (for text-independent speaker ID)
sidOpt.useGtEpd=0; % Use GT EPD labelled by human, only available for "mir-2010-speakerId_label"
sidOpt.epdFcn='epdByVol'; % epdByVol is better for GMM.
% ====== Corpus directories
%sidOpt.auDir01='d:/dataset/鈦映科技-2008-語者辨識/第一次錄音檔(100人)'; % Session 1
%sidOpt.auDir02='d:/dataset/鈦映科技-2008-語者辨識/第二次錄音檔(100人)'; % Session 2
sidOpt.auDir01='d:\dataSet\mir-2010-speakerId_label\session01'; % Session 1, with GT ednpoints
sidOpt.auDir02='d:\dataSet\mir-2010-speakerId_label\session02'; % Session 2, with GT ednpoints
% ====== Output dirs and files
[parentDir, mainName]=fileparts(fileparts(sidOpt.auDir01));
sidOpt.outputDir=['output/', mainName]; % Output directory, such as 'mir-2010-speakerId_label'
sidOpt.errorLogFile=[sidOpt.outputDir, '/error.log'];
% ====== Use partial data for fast verification
sidOpt.maxSpeakerNum=3;
sidOpt.maxSpeakerNum=inf;
sidOpt.sentenceNumPerSpeaker=3; % Use 3 utterance (1 password) per person, for fast computation
sidOpt.sentenceNumPerSpeaker=inf;
% === Evaluation mode
sidOpt.mixData=0; % 1 for mix mode (two datasets are mixed, odd-indexed for training and even-indexed for testing)
% ====== Feature/waveform related
% === Feature type
sidOpt.feaType='mfcc'; % 'mfcc', 'spectrum', 'volume', 'pitch'
sidOpt.useEnergy=1; % mfcc dim=13 if useEnergy = 1; mfcc dim=12 if useEnergy=0
% === Temporal normalization mode
sidOpt.temporalNormMode=1; % 0: nothing, 1: CMS (cepstrum mean subtraction), 2: CN (cepstrum normalization)
% === Feature transformation mode
sidOpt.feaTransformMode=0; % 0: nothing, 1: LDA, 2: PCA
sidOpt.transformedFeaDim=10; % This is used only when the above option is 1 or 2
% === Feature/waveform options
sidOpt.useWaveformNormalization=0; % 0 or 1
% === Use integer feature for embedded devices
sidOpt.useIntFea=0; % Use integer feature (MFCC) for smartphone
switch(sidOpt.method)
case 'gmm' % ====== GMM parameters
% === GMM model parameters
sidOpt.exponent4gaussianNum=1:8;
sidOpt.gaussianNums=2.^sidOpt.exponent4gaussianNum;
sidOpt.covType=1;
% === GMM training parameters
sidOpt.gmmTrainParam.dispOpt=0;
sidOpt.gmmTrainParam.useKmeans=1;
sidOpt.gmmTrainParam.maxIteration=50;
% === Use integer GMM for smartphone
sidOpt.useIntGmm=0;
case 'dtw' % ====== DTW parameters
% === DTW type
sidOpt.dtwFunc='dtw2'; % Set this to 'dtw1' (27-45-63) or 'dtw2' (0-45-90)
sidOpt.useDtwPartialComputation=0; % Speedup via partial computation (does not speed up significantly)
otherwise
error('Unknown method!');
end
And we need to create the output folder if it doesn't exist:
if ~exist(sidOpt.outputDir, 'dir'), fprintf('Creating %s...\n', sidOpt.outputDir); mkdirs(sidOpt.outputDir); end
Dataset construction
Here we have some facts about the speaker-ID corpus for this tutorial:
- All the audio clips are recorded by a single mobile phone to reduce channel distortion.
- Each person is required to record 3 times for each of 10 speech passwords, leading to a total of 30 clips per person.
- We have close to 100 persons for the recordings.
- There are 2 sessions for recordings with a week apart. We shall use recordings in session 1 as the training data and those in session 2 as the test data.
To collect all the audio files and perform feature extraction, we can invoke "sidFeaExtract" as follows:
tic
[speakerSet1, speakerSet2]=sidFeaExtract(sidOpt);
fprintf('Elapsed time = %g sec\n', toc);
Loading output/mir-2010-speakerId_label/speakerSet.mat... sidFeaExtract ===> 0.577 seconds Elapsed time = 0.623752 sec
Note the extracted data will be stored as a mat file for future use.
To evaluate the performance, we can invoke "sidPerfEval":
tic [overallRr, speakerSet1, time]=sidPerfEval(speakerSet1, speakerSet2, sidOpt, 1); fprintf('Elapsed time = %g sec\n', toc); fprintf('Saving %s/speakerSet1.mat...\n', sidOpt.outputDir); eval(sprintf('save %s/speakerSet1 speakerSet1', sidOpt.outputDir));
1/97: speaker=Kannan#1 RR for Kannan#1 = 100.00%, ave. time = 0.09 sec 2/97: speaker=丁凱元#1 RR for 丁凱元#1 = 100.00%, ave. time = 0.08 sec 3/97: speaker=任佳王民#1 RR for 任佳王民#1 = 83.33%, ave. time = 0.07 sec 4/97: speaker=劉俊宏#1 RR for 劉俊宏#1 = 100.00%, ave. time = 0.08 sec 5/97: speaker=劉怡芬#0 RR for 劉怡芬#0 = 100.00%, ave. time = 0.10 sec 6/97: speaker=卓楷斌#1 RR for 卓楷斌#1 = 100.00%, ave. time = 0.10 sec 7/97: speaker=吳亮辰#1 RR for 吳亮辰#1 = 100.00%, ave. time = 0.10 sec 8/97: speaker=吳俊慶#1 RR for 吳俊慶#1 = 100.00%, ave. time = 0.10 sec 9/97: speaker=吳偉廷#1 RR for 吳偉廷#1 = 100.00%, ave. time = 0.09 sec 10/97: speaker=吳明儒#1 RR for 吳明儒#1 = 93.33%, ave. time = 0.09 sec 11/97: speaker=周哲民#1 RR for 周哲民#1 = 96.67%, ave. time = 0.08 sec 12/97: speaker=周哲玄#1 RR for 周哲玄#1 = 76.67%, ave. time = 0.08 sec 13/97: speaker=周進財#1 RR for 周進財#1 = 100.00%, ave. time = 0.07 sec 14/97: speaker=周進雄#1 RR for 周進雄#1 = 100.00%, ave. time = 0.06 sec 15/97: speaker=唐若華#0 RR for 唐若華#0 = 100.00%, ave. time = 0.09 sec 16/97: speaker=廖育志#1 RR for 廖育志#1 = 100.00%, ave. time = 0.10 sec 17/97: speaker=廖韋嵐#0 RR for 廖韋嵐#0 = 100.00%, ave. time = 0.10 sec 18/97: speaker=張智星#1 RR for 張智星#1 = 100.00%, ave. time = 0.09 sec 19/97: speaker=彭郁雅#0 RR for 彭郁雅#0 = 86.67%, ave. time = 0.10 sec 20/97: speaker=徐偉智#1 RR for 徐偉智#1 = 100.00%, ave. time = 0.11 sec 21/97: speaker=徐君潔#0 RR for 徐君潔#0 = 100.00%, ave. time = 0.10 sec 22/97: speaker=徐培霖#1 RR for 徐培霖#1 = 100.00%, ave. time = 0.09 sec 23/97: speaker=徐懿荷#0 RR for 徐懿荷#0 = 93.33%, ave. time = 0.09 sec 24/97: speaker=徐韻媜#0 RR for 徐韻媜#0 = 96.67%, ave. time = 0.07 sec 25/97: speaker=方一帆#1 RR for 方一帆#1 = 100.00%, ave. time = 0.08 sec 26/97: speaker=曾泓熹#1 RR for 曾泓熹#1 = 93.33%, ave. time = 0.10 sec 27/97: speaker=朋瑞雲#0 RR for 朋瑞雲#0 = 100.00%, ave. time = 0.08 sec 28/97: speaker=李函軒#1 RR for 李函軒#1 = 100.00%, ave. time = 0.10 sec 29/97: speaker=李哲維#1 RR for 李哲維#1 = 100.00%, ave. time = 0.09 sec 30/97: speaker=李宗奇#1 RR for 李宗奇#1 = 100.00%, ave. time = 0.08 sec 31/97: speaker=李怡欣#0 RR for 李怡欣#0 = 86.67%, ave. time = 0.08 sec 32/97: speaker=李芝宇#0 RR for 李芝宇#0 = 100.00%, ave. time = 0.10 sec 33/97: speaker=李藺芳#0 RR for 李藺芳#0 = 100.00%, ave. time = 0.10 sec 34/97: speaker=杜承恩#1 RR for 杜承恩#1 = 100.00%, ave. time = 0.09 sec 35/97: speaker=林佳廷#1 RR for 林佳廷#1 = 96.67%, ave. time = 0.09 sec 36/97: speaker=林志翰#1 RR for 林志翰#1 = 96.67%, ave. time = 0.10 sec 37/97: speaker=林應耀#1 RR for 林應耀#1 = 100.00%, ave. time = 0.10 sec 38/97: speaker=林昱豪#1 RR for 林昱豪#1 = 90.00%, ave. time = 0.08 sec 39/97: speaker=林琪家#1 RR for 林琪家#1 = 86.67%, ave. time = 0.07 sec 40/97: speaker=林立緯#1 RR for 林立緯#1 = 83.33%, ave. time = 0.09 sec 41/97: speaker=林美慧#0 RR for 林美慧#0 = 100.00%, ave. time = 0.10 sec 42/97: speaker=梁啟輝#1 RR for 梁啟輝#1 = 100.00%, ave. time = 0.08 sec 43/97: speaker=楊子睿#1 RR for 楊子睿#1 = 96.67%, ave. time = 0.07 sec 44/97: speaker=楊宗樺#1 RR for 楊宗樺#1 = 93.33%, ave. time = 0.08 sec 45/97: speaker=楊惠敏#0 RR for 楊惠敏#0 = 100.00%, ave. time = 0.10 sec 46/97: speaker=楊振緯#1 RR for 楊振緯#1 = 80.00%, ave. time = 0.09 sec 47/97: speaker=江育儒#1 RR for 江育儒#1 = 93.33%, ave. time = 0.08 sec 48/97: speaker=汪世婕#0 RR for 汪世婕#0 = 96.67%, ave. time = 0.07 sec 49/97: speaker=汪緒中#1 RR for 汪緒中#1 = 100.00%, ave. time = 0.10 sec 50/97: speaker=游鎮洋#1 RR for 游鎮洋#1 = 100.00%, ave. time = 0.08 sec 51/97: speaker=王俊凱#1 RR for 王俊凱#1 = 100.00%, ave. time = 0.08 sec 52/97: speaker=王小龜#1 RR for 王小龜#1 = 96.67%, ave. time = 0.09 sec 53/97: speaker=王怡萱#0 RR for 王怡萱#0 = 96.67%, ave. time = 0.09 sec 54/97: speaker=王瑩#0 RR for 王瑩#0 = 73.33%, ave. time = 0.08 sec 55/97: speaker=王美玲#0 RR for 王美玲#0 = 100.00%, ave. time = 0.10 sec 56/97: speaker=白宗儒#1 RR for 白宗儒#1 = 100.00%, ave. time = 0.10 sec 57/97: speaker=簡嘉宏#1 RR for 簡嘉宏#1 = 100.00%, ave. time = 0.08 sec 58/97: speaker=簡祐祥#1 RR for 簡祐祥#1 = 43.33%, ave. time = 0.07 sec 59/97: speaker=羅尹聰#1 RR for 羅尹聰#1 = 100.00%, ave. time = 0.09 sec 60/97: speaker=胡任桓#1 RR for 胡任桓#1 = 100.00%, ave. time = 0.09 sec 61/97: speaker=葉子雋#1 RR for 葉子雋#1 = 100.00%, ave. time = 0.08 sec 62/97: speaker=董姵汝#0 RR for 董姵汝#0 = 100.00%, ave. time = 0.09 sec 63/97: speaker=蔡佩京#0 RR for 蔡佩京#0 = 100.00%, ave. time = 0.07 sec 64/97: speaker=蔡耀陞#1 RR for 蔡耀陞#1 = 100.00%, ave. time = 0.09 sec 65/97: speaker=薛光利#0 RR for 薛光利#0 = 100.00%, ave. time = 0.09 sec 66/97: speaker=蘇雅雯#0 RR for 蘇雅雯#0 = 90.00%, ave. time = 0.07 sec 67/97: speaker=衛帝安#1 RR for 衛帝安#1 = 96.67%, ave. time = 0.10 sec 68/97: speaker=許凱華#1 RR for 許凱華#1 = 100.00%, ave. time = 0.08 sec 69/97: speaker=許書豪#1 RR for 許書豪#1 = 100.00%, ave. time = 0.09 sec 70/97: speaker=謝僑威#1 RR for 謝僑威#1 = 96.67%, ave. time = 0.08 sec 71/97: speaker=賴俊龍#1 RR for 賴俊龍#1 = 100.00%, ave. time = 0.10 sec 72/97: speaker=賴郡曄#1 RR for 賴郡曄#1 = 83.33%, ave. time = 0.07 sec 73/97: speaker=邱莉婷#0 RR for 邱莉婷#0 = 93.33%, ave. time = 0.10 sec 74/97: speaker=郭哲綸#1 RR for 郭哲綸#1 = 100.00%, ave. time = 0.10 sec 75/97: speaker=郭湧鈐#1 RR for 郭湧鈐#1 = 100.00%, ave. time = 0.08 sec 76/97: speaker=鄭宇志#1 RR for 鄭宇志#1 = 100.00%, ave. time = 0.10 sec 77/97: speaker=鄭鈞蔚#1 RR for 鄭鈞蔚#1 = 100.00%, ave. time = 0.07 sec 78/97: speaker=陳亦敦#1 RR for 陳亦敦#1 = 100.00%, ave. time = 0.10 sec 79/97: speaker=陳亮宇#1 RR for 陳亮宇#1 = 100.00%, ave. time = 0.09 sec 80/97: speaker=陳俊達#1 RR for 陳俊達#1 = 100.00%, ave. time = 0.10 sec 81/97: speaker=陳偉豪#1 RR for 陳偉豪#1 = 96.67%, ave. time = 0.06 sec 82/97: speaker=陳冠宇#1 RR for 陳冠宇#1 = 100.00%, ave. time = 0.10 sec 83/97: speaker=陳威翰#1 RR for 陳威翰#1 = 100.00%, ave. time = 0.09 sec 84/97: speaker=陳宏瑞#1 RR for 陳宏瑞#1 = 96.67%, ave. time = 0.08 sec 85/97: speaker=陳揚昇#1 RR for 陳揚昇#1 = 100.00%, ave. time = 0.10 sec 86/97: speaker=陳易正#1 RR for 陳易正#1 = 96.67%, ave. time = 0.10 sec 87/97: speaker=陳朝煒#1 RR for 陳朝煒#1 = 100.00%, ave. time = 0.08 sec 88/97: speaker=陳杰興#1 RR for 陳杰興#1 = 96.67%, ave. time = 0.09 sec 89/97: speaker=陳永強#1 RR for 陳永強#1 = 96.67%, ave. time = 0.09 sec 90/97: speaker=高佳慧#0 RR for 高佳慧#0 = 100.00%, ave. time = 0.10 sec 91/97: speaker=魏宇晨#0 RR for 魏宇晨#0 = 100.00%, ave. time = 0.09 sec 92/97: speaker=黃昌傑#1 RR for 黃昌傑#1 = 100.00%, ave. time = 0.10 sec 93/97: speaker=黃永漢#1 RR for 黃永漢#1 = 100.00%, ave. time = 0.07 sec 94/97: speaker=黃秀惠#0 RR for 黃秀惠#0 = 86.67%, ave. time = 0.07 sec 95/97: speaker=黃羿銘#1 RR for 黃羿銘#1 = 100.00%, ave. time = 0.10 sec 96/97: speaker=黃韋中#1 RR for 黃韋中#1 = 83.33%, ave. time = 0.09 sec 97/97: speaker=龍慧容#0 RR for 龍慧容#0 = 90.00%, ave. time = 0.08 sec Ovderall RR = 96.22% Elapsed time = 256.515 sec Saving output/mir-2010-speakerId_label/speakerSet1.mat...
Post analysis
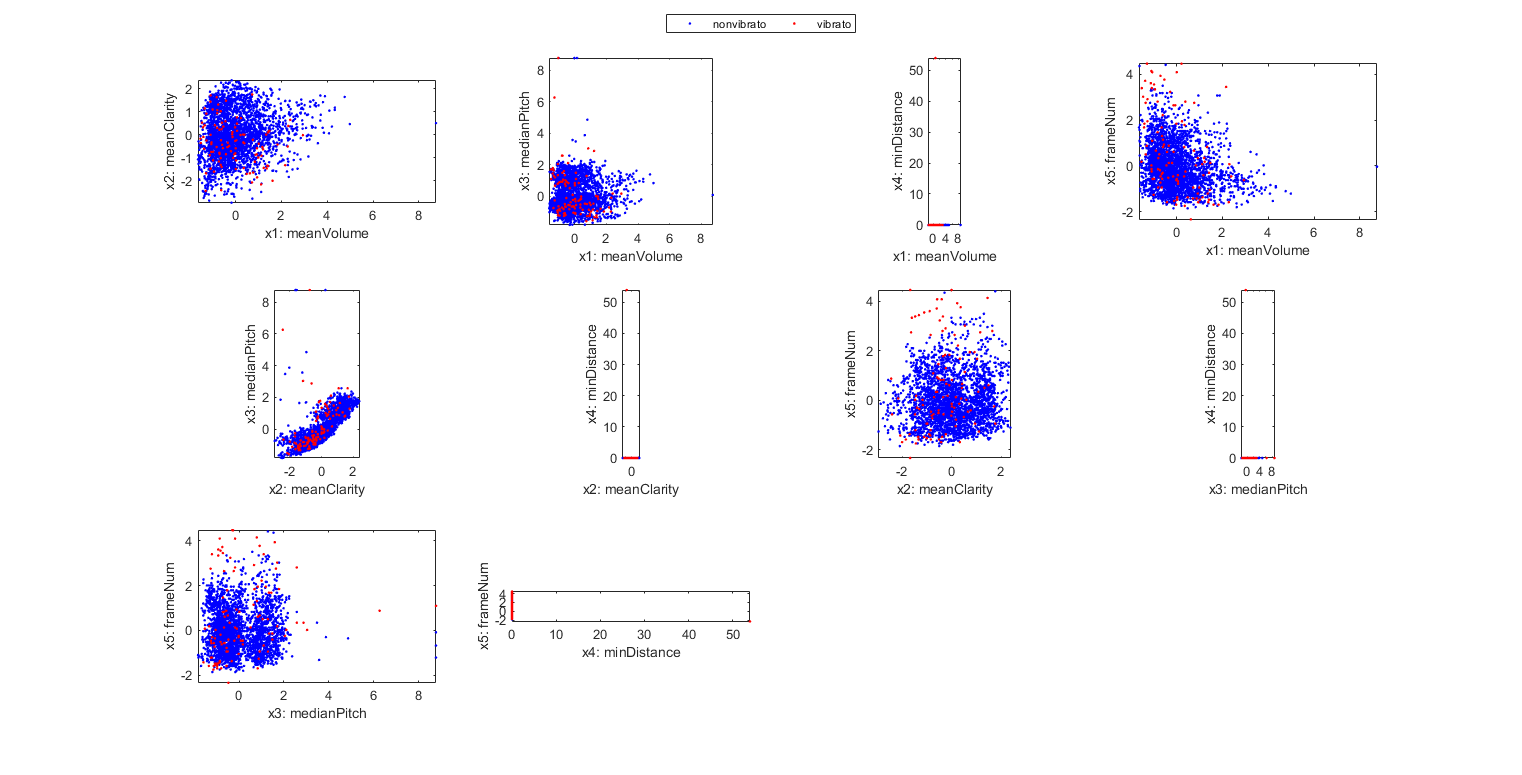
We can display the scatter plots based on the features of each sentence, in order to visualize if it is possible to separate "bad" utterances from "good" ones:
sentence=[speakerSet1.sentence];
DS.input=[[sentence.meanVolume]; [sentence.meanClarity]; [sentence.medianPitch]; [sentence.minDistance]; [sentence.frameNum]];
DS.inputName={'meanVolume', 'meanClarity', 'medianPitch', 'minDistance', 'frameNum'};
DS.input=inputNormalize(DS.input);
DS.output=2-[sentence.correct];
dsProjPlot2(DS); figEnlarge;
eval(sprintf('print -dpng %s/dtwDataDistribution', sidOpt.outputDir));
Summary
This is a brief tutorial on text-dependent speaker recognition based on DTW. There are several directions for further improvement:
- Explore other features, such as magnitude spectra or filter bank coefficients.
- Try flexible anchor positions for DTW.
- Use rejection to improve the overall system's accuracy.
Appendix
List of functions used in this script
Overall elapsed time:
toc(scriptStartTime)
Elapsed time is 261.217299 seconds.
Jyh-Shing Roger Jang, created on
datetime
ans = datetime 18-Jan-2020 20:58:51
If you are interested in the original MATLAB code for this page, you can type "grabcode(URL)" under MATLAB, where URL is the web address of this page.